为什么识别出的字幕长短不一乱七八糟-如何优化调整?
在视频翻译过程中,经语音识别阶段自动生成的字幕,效果常常不理想。要么字幕过长,几乎占满屏幕;要么只显示两三个字符,显得七零八落。为什么会出现这种情况呢?
语音识别的断句标准
语音识别:
即人类说话声音转换为文字字幕时,通常是根据静音区间来切割句子。一般来说,静音片段的时长设定在200毫秒到500毫秒之间。假设设定为250毫秒,当检测到静音持续达到250毫秒时,程序就会将其视为一句话的结束点。此时,从上一个结束点到这里生成一条字幕。
影响字幕效果的因素
- 说话速度
如果音频中讲话速度很快,几乎没有停顿,或者停顿时间不足250毫秒,切割出的字幕会很长,可能持续十几秒甚至几十秒,嵌入视频时会占满屏幕。

- 不规则停顿:
相反,如果说话时出现了不该有的停顿,例如本是连贯的一句话中间却停顿几次,切割出来的字幕会非常零碎,可能一条字幕只显示几个字。

- 背景噪声
背景噪声或音乐也会干扰静音区间的判断,导致识别不准确。
- 发音清晰度:这个显而易见,发音不清时连人类都无法听清
如何应对这些问题?
- 减少背景噪声:
如果背景噪声较大,可以在识别前进行人声与背景声的分离,去除干扰声,以提高识别效果。
- 使用大体积的语音识别模型:
计算机性能允许的情况下,尽量使用大模型进行识别,比如 large-v2 或 large-v3-turbo。
- 调整静音片段时长:
软件默认将静音片段设为200毫秒。根据音视频的具体情况,可以调整这个值。如果你想识别的视频说话速度较快,可以降低到100毫秒;如果停顿较多,可以增加到300或500毫秒。设置方法是打开菜单中的工具/选项,然后选择高级选项,在faster/openai语音识别调整部分修改最小静音片段值。
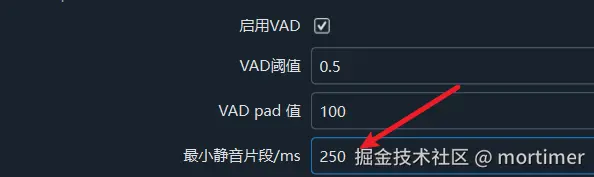
- 设置字幕最大持续时长:
可以设定字幕的最大时长,超出该时长的字幕会被强制断句。该设置同样在高级选项中。
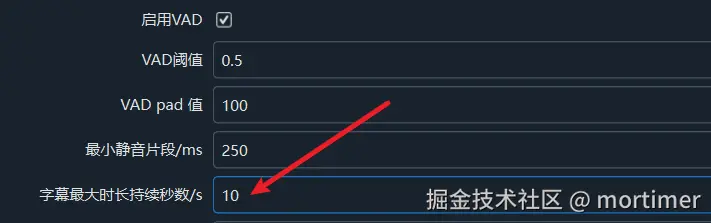
如图所示,超过10秒的字幕会被重新切割。
- 设置一行字幕的最大字符数:
可以设置每行字幕的字符数上限,超出字符数的字幕将自动换行或断句。
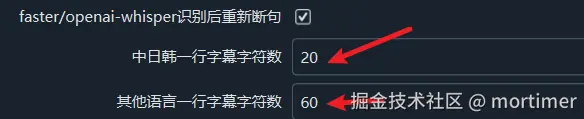
- 开启重新断句功能:开启此选项后,结合上面提到的第4条和第5条设置,程序会自动重新断句。
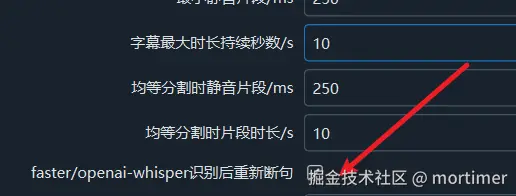
经过以上 3、4、5、6 设置,程序会先根据静音区间生成字幕,遇到超长字幕或字符数过多时,程序会通过重新断句来分割字幕。重新断句分割字幕时,程序使用了 nltk 自然语言处理库,结合静音区间时长、标点符号、字幕字符数量等综合判断后分割。