提高AI翻译字幕的质量
在使用AI翻译srt字幕时,通常有两种方式。
方式一:带字幕格式完整翻译,包括无需翻译的“行号”、“时间戳行”。
如下示例,带格式完整发送
1
00:00:01,950 --> 00:00:04,950
五老星系中发现了有机分子.
2
00:00:04,950 --> 00:00:07,902
我们离第三类接触还有多元。
3
00:00:07,902 --> 00:00:11,958
微波真是展开拍摄任务已经进来周年。优点 兼顾上下文,翻译质量较好。
缺点 除了浪费token外,还有可能在翻译中导致字幕格式错乱,返回的翻译结果不再是合法是srt字幕格式。例如英文符号 ,: 可能被错误的改为中文符号,或将行号时间行合为一行等。
方式二:只发送字幕文本内容,然后再将翻译结果替换原字幕中对应文本。
如下格式,仅发送字幕文字
五老星系中发现了有机分子.
我们离第三类接触还有多元。
微波真是展开拍摄任务已经进来周年。优点 能保证翻译结果一定是合法的srt字幕格式。
缺点 也很明显,一行一行的字幕文本翻译,无法兼顾上下文,翻译质量大为降低。
为解决这个问题,软件中支持一次性翻译多行,默认15行字幕,可一定程度上照应上下文。
但随之又引出一个新问题:不同语言语法规则、语句结构顺序有所不同,很可能出现原文是15行,翻译后变为了14行、13行等,特别是前面一行和后面一行在语法结构上是同一句子时。

15行原字幕翻译后不再是15行,这肯定导致字幕混乱,为解决这个问题,当翻译结果和原字幕行数不一致时,则重新一行一行翻译,确保前后字幕行数完全一致,舍弃照应上下文。
软件中默认使用的第二种方式,毕竟能用比好用更重要。
从版本v2.52起,新增了 第一种翻译方式 支持,默认不启用,如果想启用,需要手动开启,开启后,在使用ChatGPT/Gemini/AzureGPT/302.AI/字节火山/LocalLLM这些AI进行翻译时,将会完整发送带格式srt字幕进行翻译,能更好的照应上下文,提高翻译质量。
但必须注意, 第一种方式提到的问题可能会出现,导致结果不是合法srt字幕,可能出现解析错误或丢失错误之后的所有内容。建议只在足够智能的模型上使用该方式,例如 GPT-4o-mini或更大的模型,如果是本地部署的模型,不建议采用该方式,受限于硬件资源,本地部署的模型一般规模很小,不够智能,更容易出现翻译结果格式混乱。
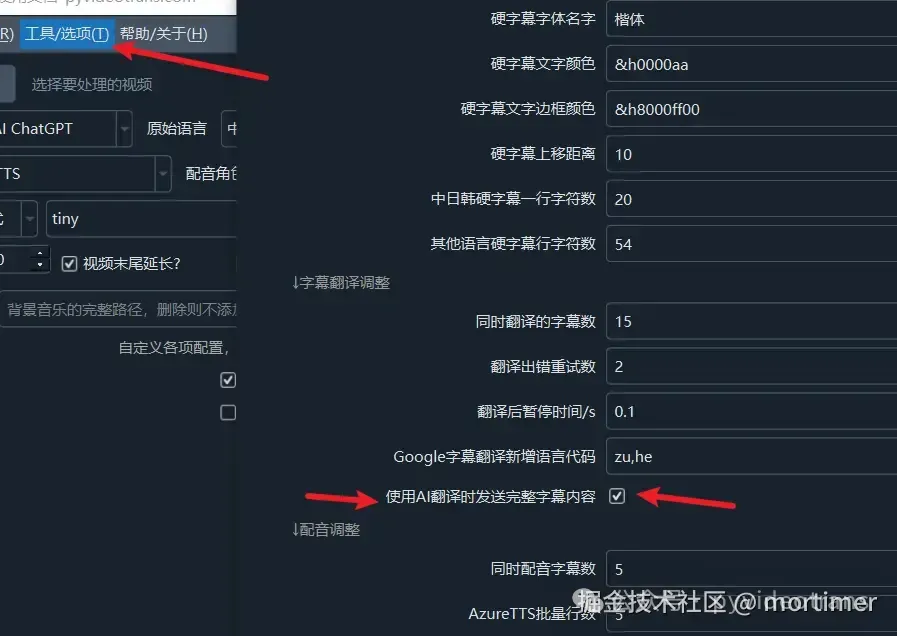
开启第一种翻译方法:
菜单--工具/选项--高级选项--字幕翻译区域--AI智能翻译时发送完整字幕
增加术语表
每种提示词中均可添加自己的术语表,类似如下
**在翻译过程中,务必使用** 我提供的术语表进行术语的翻译,保持术语的一致性。具体术语表如下:
* Transformer -> Transformer
* Token -> Token
* LLM/Large Language Model -> 大语言模型
* Generative AI -> 生成式 AI
* One Health -> One Health
* Radiomics -> 影像组学
* OHHLEP -> OHHLEP
* STEM -> STEM
* SHAPE -> SHAPE
* Single-cell transcriptomics -> 单细胞转录组学
* Spatial transcriptomics -> 空间转录组学