pyVideoTrans视频翻译软件:是一款将视频从一种语言转换到另一种语言发音和字幕的软件。
它能够识别原视频中的说话声,自动生成字幕,并将字幕翻译为另一种语言,同时使用该语言配音,从而创建出含有所指定语言配音和字幕的新视频,实现视频翻译。
语音识别支持 faster-whisper和openai-whisper本地离线模型 及 OpenAI SpeechToText API GoogleSpeech 阿里中文语音识别模型和豆包模型,并支持自定义语音识别api.
字幕翻译支持 微软翻译|Google翻译|百度翻译|腾讯翻译|ChatGPT|AzureAI|Gemini|DeepL|DeepLX|字节火山|离线翻译OTT
语音合成支持 Microsoft Edge tts Google tts Azure AI TTS Openai TTS Elevenlabs TTS 自定义TTS服务器api GPT-SoVITS clone-voice ChatTTS-ui Fish TTS CosyVoice F5-TTS
支持的语言:中文简繁、英语、韩语、日语、俄语、法语、德语、意大利语、西班牙语、葡萄牙语、越南语、泰国语、阿拉伯语、土耳其语、匈牙利语、印度语、乌克兰语、哈萨克语、印尼语、马来语、捷克语、波兰语、荷兰语、瑞典语/其他语言可选自动检测
软件工作原理
本软件通过识别视频中的说话声音来进行翻译和处理,与视频中原有的字幕无关。只要视频里有人类说话的声音,就可以进行处理,无论视频是否包含字幕。
需要注意的是:
- 如果视频中只有字幕而没有说话声音,本软件无法处理。
- 本软件不能直接提取或识别视频中已有的字幕文件。
下载软件
下载解压方式仅适用于Windows系统,Mac和Linux请源码安装
- 打开软件官网:https://pyvideotrans.com/
- 点击下载按钮,进入下载页面:https://pyvideotrans.com/downpackage.html
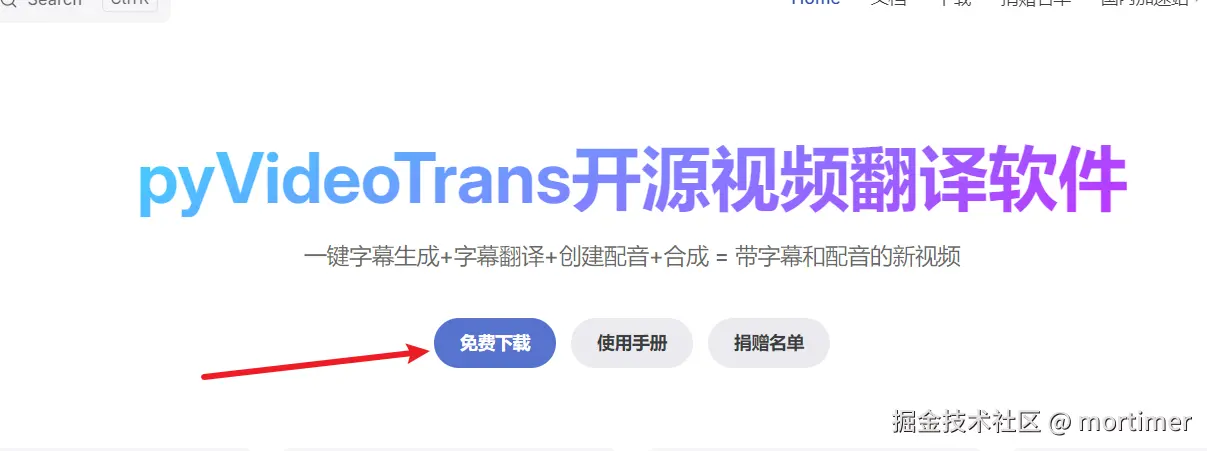
- 选择百度网盘下载地址,下载完整安装包和最新的补丁包。
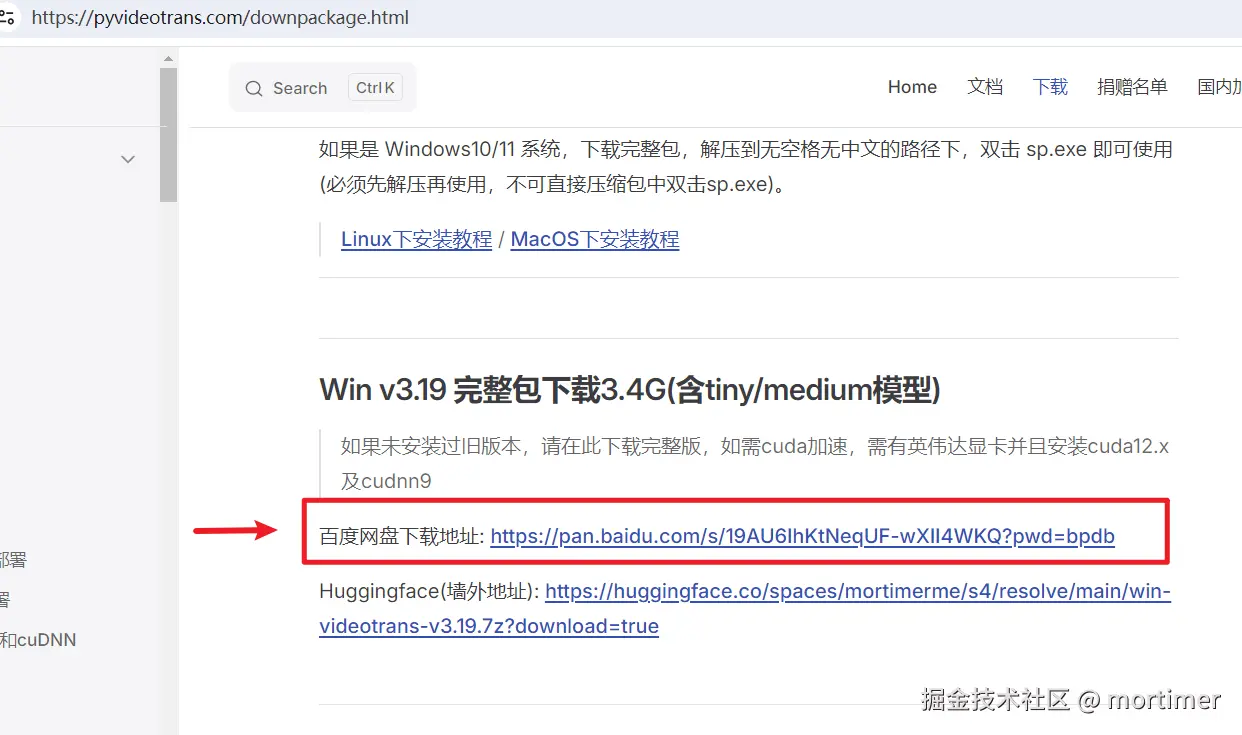
首次使用,必须下载完整安装包。 下载补丁包后,将其解压并覆盖到完整安装包解压后的目录中。
解压安装包
下载解压方式仅适用于Windows系统,Mac和Linux请源码安装
下载的完整包和补丁包都是 7z 压缩包格式。可以使用 7-Zip 或其他解压缩软件进行解压。
推荐使用 360压缩软件:

解压注意事项:
- 避免权限问题: 不要将软件解压到桌面或 C 盘的
Program Files等需要管理员权限的文件夹下。 - 避免路径错误: 解压路径中不要包含中文、空格或特殊符号。
强烈建议: 在 D 盘或 E 盘等非系统盘下创建一个新的英文或数字命名的文件夹,并将软件解压到该文件夹内。例如:D:/videotrans。
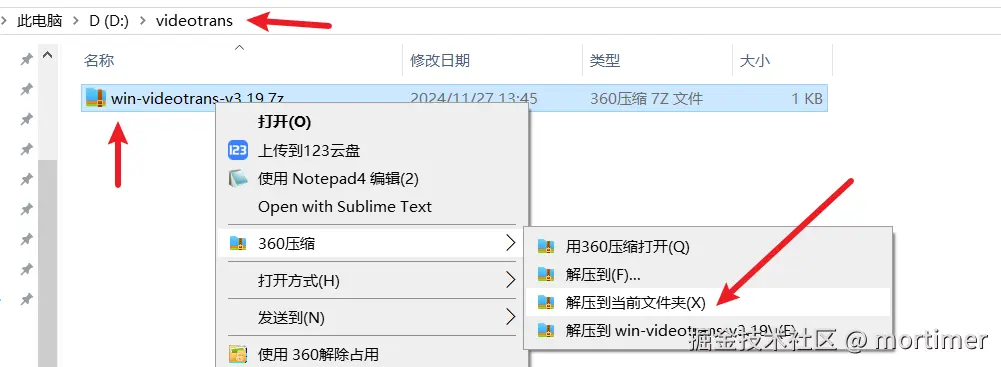
解压后,找到 sp.exe 文件,双击即可启动软件。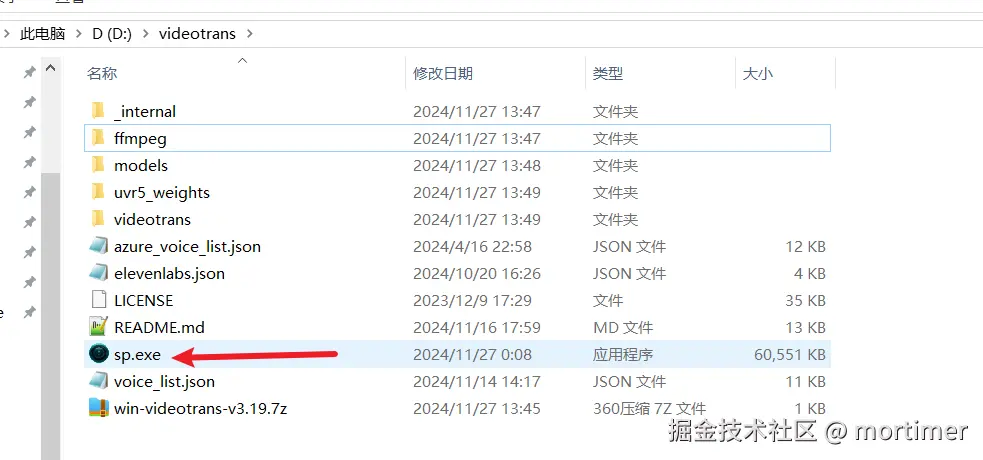
启动软件
sp.exe启动方式仅适用于Windows系统,Mac和Linux请源码安装
双击 sp.exe 启动软件。由于软件使用了 PySide6 构建界面并内置了较多的功能模块,启动可能需要一些时间,请耐心等待。
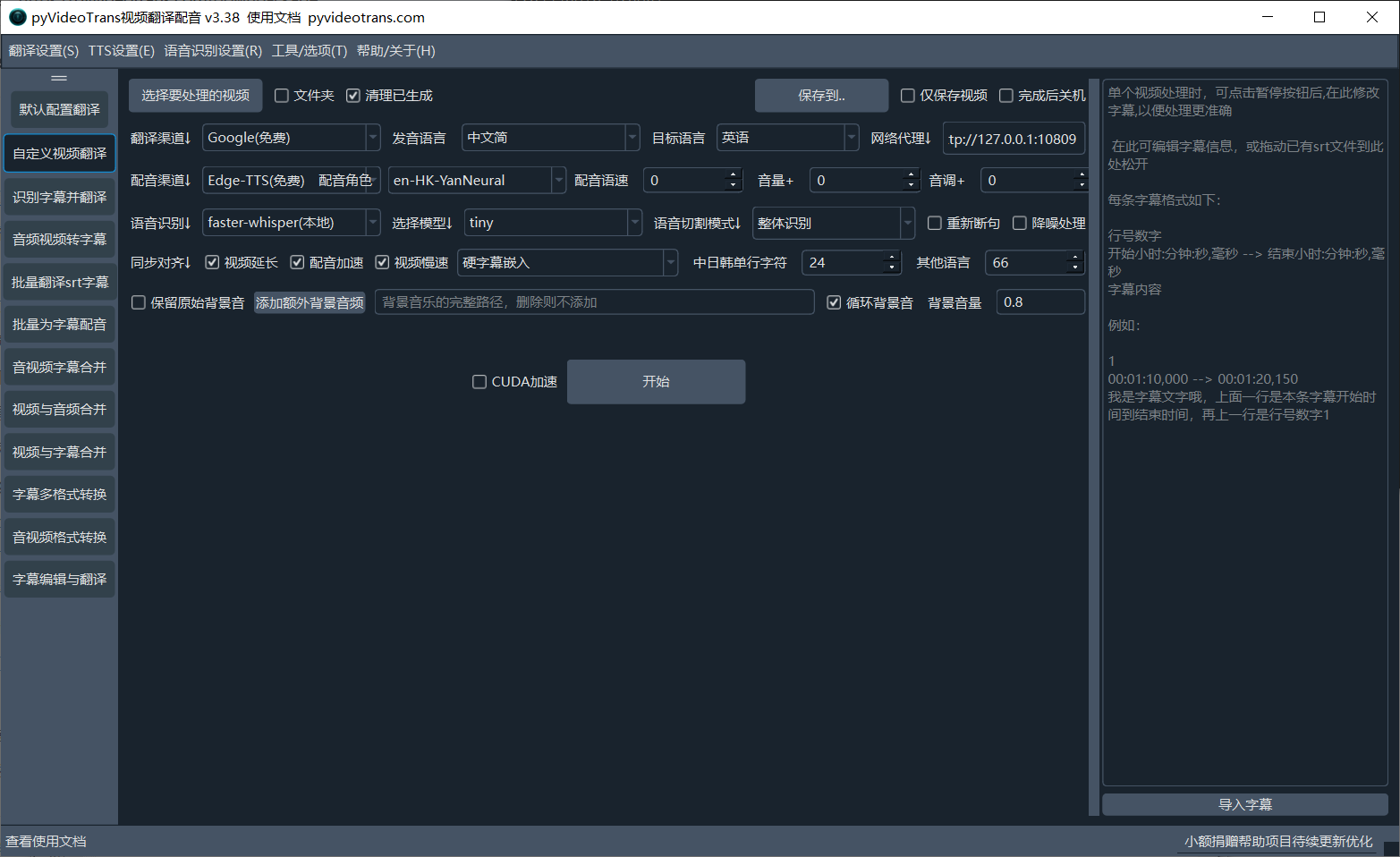
启动成功后,将显示软件主界面:
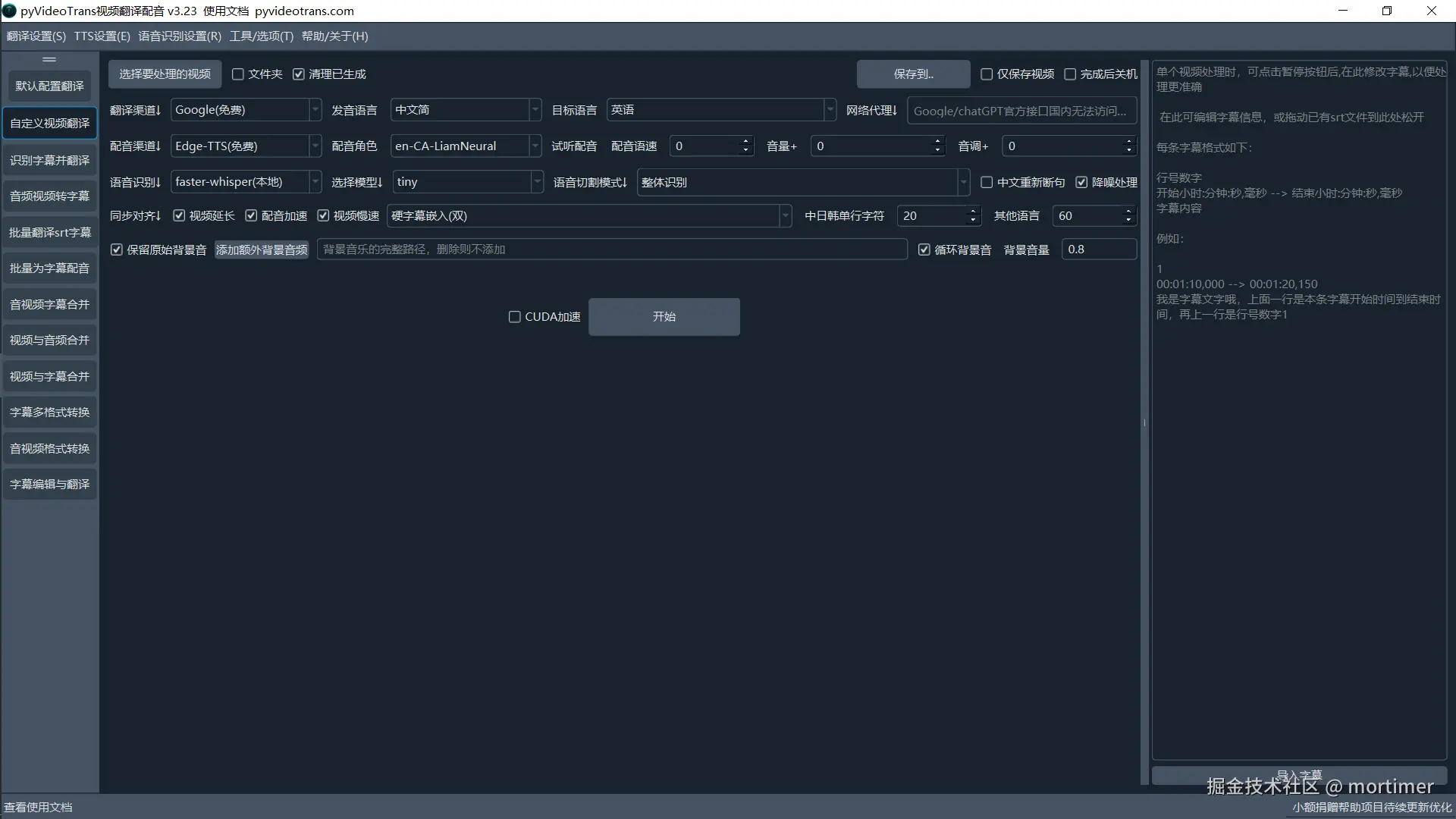
界面说明:
- 左上角标题栏: 显示软件版本号。
- 左下角: 点击可打开软件文档站。
- 菜单栏: 包含翻译、配音等渠道的设置选项,以及帮助和关于信息。
- 左侧按钮: 各个功能模块,视频翻译主要使用
默认配置翻译和自定义视频翻译两个按钮。默认配置翻译使用简单,但翻译效果一般;自定义视频翻译提供更多自定义选项,可以获得更好的翻译效果。 建议使用自定义视频翻译。
视频翻译操作步骤
软件默认打开 自定义视频翻译 模块,右侧是操作区域。
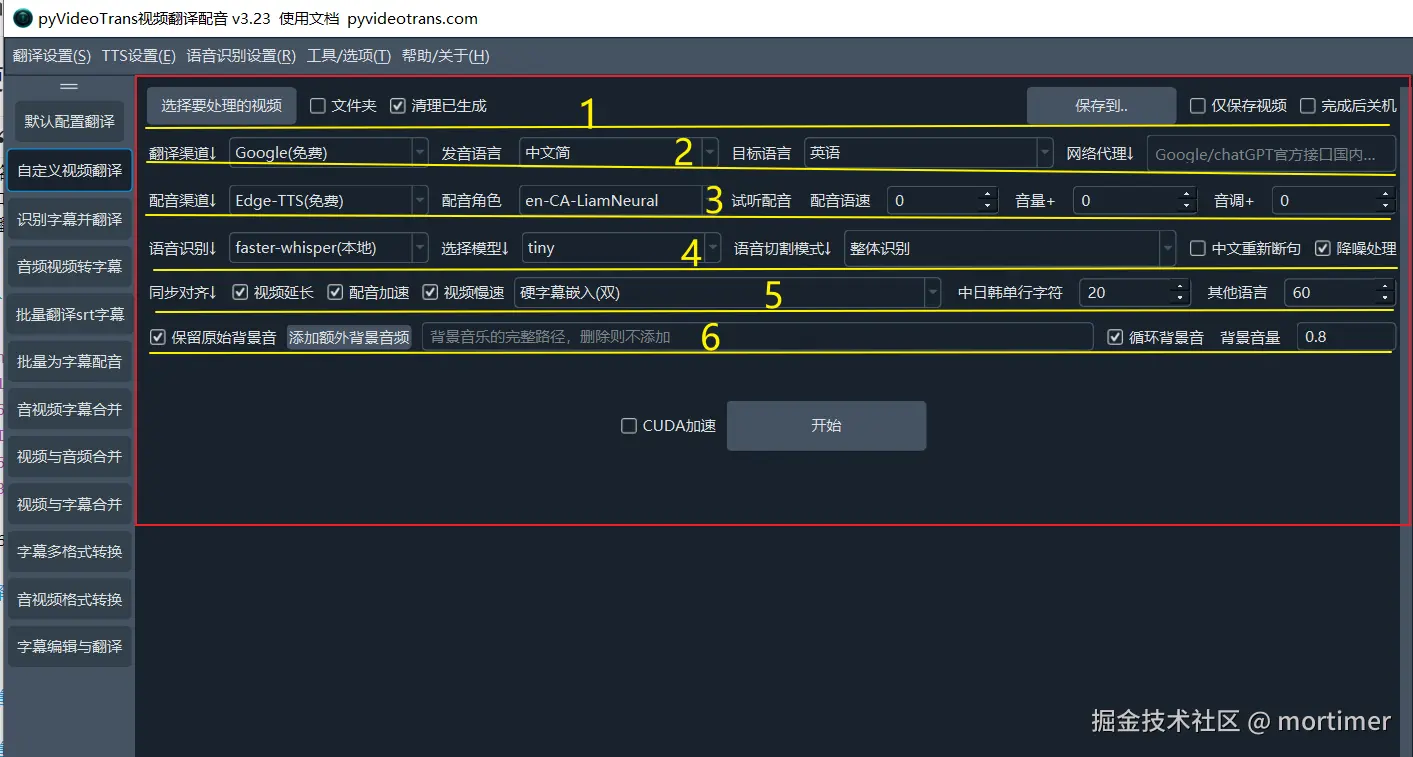
操作区域包含以下 6 个部分:
1. 选择需要翻译的原始视频

选择要处理的视频: 点击按钮,从电脑中选择一个或多个视频文件 (按住 Ctrl 键可多选)。文件夹: 选中此复选框,可以选择一个文件夹,软件将批量翻译该文件夹下的所有视频文件。清理已生成: 如果对同一个视频再次进行操作,默认会使用上次生成的缓存数据。如果需要重新生成所有文件,请选中此复选框。保存到..: 点击按钮,选择翻译后文件的保存位置。默认保存在原始视频所在目录下的_video_out文件夹中。仅保存视频: 翻译过程中会生成字幕文件、音频文件等中间文件。如果只需要最终的翻译视频,请选中此复选框。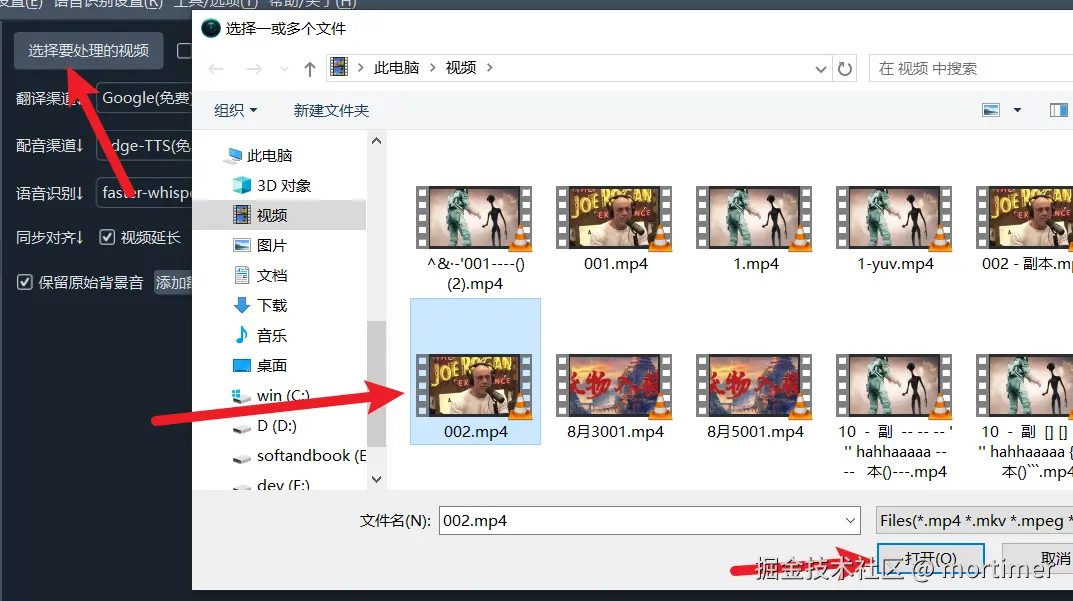
2. 选择翻译渠道

本软件会先将视频语音转换为字幕,然后再将字幕翻译成目标语言,翻译渠道用来完成字幕翻译工作。
翻译渠道: 选择字幕翻译渠道。微软翻译: 免费,无需 VPN,翻译质量一般。 (默认选项)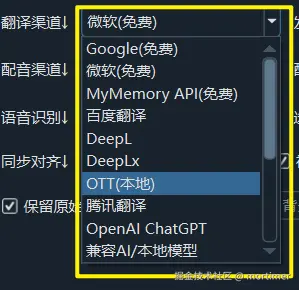
Google: 翻译质量较好,需要 VPN。OpenAI ChatGPT: 翻译质量最佳,需要 VPN 和付费账号,建议使用chatgpt-4o或更新的模型。百度翻译/腾讯翻译: 国内翻译渠道,无需 VPN,翻译质量中等。
发音语言: 选择原始视频的语音语言。目标语言: 选择需要翻译的目标语言。网络代理: 如果使用需要 VPN 的翻译渠道 (例如 Google、OpenAI),在此处填写代理 IP 和端口。
3. 选择配音渠道
翻译后的字幕文件将使用所选配音渠道生成音频文件

配音渠道: 选择配音引擎。EdgeTTS: 基于微软 Edge 浏览器的声音朗读功能,免费,无需代理。(默认选项)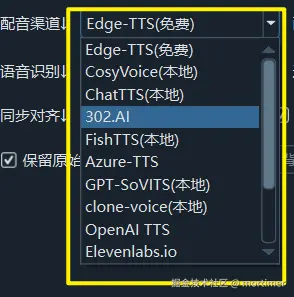
本地渠道: 需要额外安装和配置,可以在本地离线使用。- 第三方收费 API: 通常有免费试用额度。
配音角色: 选择配音角色 (例如:男声、女声)。 需要先选择目标语言才能选择配音角色。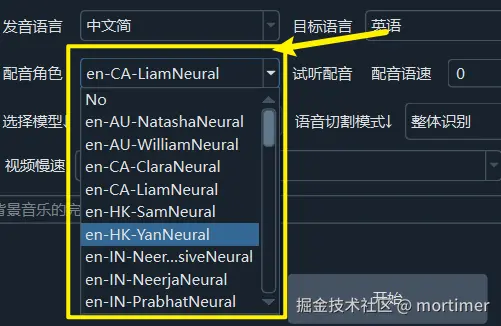
试听配音: 试听选择的配音角色效果。配音语速/音量/音调: 调整配音的语速、音量和音调。 语速和音量设置值表示相对于默认值的百分比增减量。例如,语速 15 表示比正常语速快 15% (1.15 倍速);音量 90 表示比正常音量高 90% (1.9 倍音量)。
4. 选择语音识别引擎
这是最重要的一步操作,将视频中的说话识别为文字并生成srt字幕

语音识别: 选择语音识别引擎,用于将视频语音转换为字幕。 默认选择faster-whisper,免费且可在本地运行。选择模型: 如果使用faster-whisper或openai-whisper,可以选择不同的模型。模型越大,准确度越高,但运行速度越慢,消耗的资源也越多。 软件默认只包含tiny和medium两个模型,其他模型需要单独下载。 推荐使用large-v2或large-v3-turbo模型,效果最佳 (需要英伟达显卡和 CUDA/cuDNN 支持)。语音切割模式: 选择语音切割方式。建议使用默认的整体识别模式,效果更好。均等分割模式会将语音分割成时长相等的片段, 仅在使用faster-whisper/openai-whisper时可用.中文重新断句: 选中此选项,将使用阿里云的标点符号模型对中文进行重新断句,提高字幕质量。语音降噪: 选中此选项,将使用阿里云的语音降噪模型对语音进行降噪处理,提高识别准确率。
5. 设置同步对齐

由于不同语言的语速和长度不同,翻译后的配音时长可能与原始视频不一致。 此部分用于调整字幕、配音和画面之间的同步。
视频延长: 如果配音时长超过原始视频时长,选中此选项将在视频末尾添加静止画面,使视频时长与配音时长匹配。配音加速: 如果配音时长超过原始视频时长,选中此选项将加速配音,使其时长与视频时长匹配。(最大加速倍数为 3 倍,可在菜单工具->高级选项中修改)视频慢速: 如果配音时长超过原始视频时长,选中此选项将降低视频播放速度,使其时长与配音时长匹配。(最大慢放倍数为 20 倍,可在菜单工具->高级选项中修改)字幕嵌入: 选择字幕嵌入方式。不嵌入字幕: 不在视频中嵌入字幕。嵌入硬字幕: 将字幕永久嵌入到视频中,在任何播放器中都能显示。嵌入软字幕: 将字幕作为独立文件与视频一起保存,需要播放器支持才能显示。嵌入硬字幕(双): 嵌入原始语言和目标语言两种硬字幕。嵌入软字幕(双): 嵌入原始语言和目标语言两种软字幕。
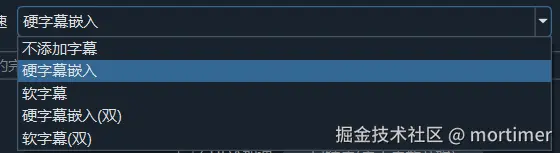
中日韩单行字符: 设置嵌入硬字幕时,中日韩语言每行字幕的最大字符数 (默认 20)。其他语言: 设置嵌入硬字幕时,其他语言每行字幕的最大字符数 (默认 60)。
6. 处理背景音

保留原始背景音: 选中此选项,将在翻译后的视频中保留原始背景音乐。注意:此选项会显著增加处理时间和系统资源消耗,并提高字幕生成的准确度。添加额外背景音频: 点击按钮,选择一个音频文件作为新的背景音乐。循环背景音: 如果新的背景音乐时长短于视频时长,选中此选项将循环播放背景音乐。背景音量: 调整背景音乐的音量。 值小于 1 为降低音量,大于 1 为提高音量。
开始执行

CUDA加速: 如果你有英伟达显卡并安装了 CUDA/cuDNN,选中此选项可以大幅提高翻译速度。
点击 开始执行 按钮,软件将开始翻译视频。
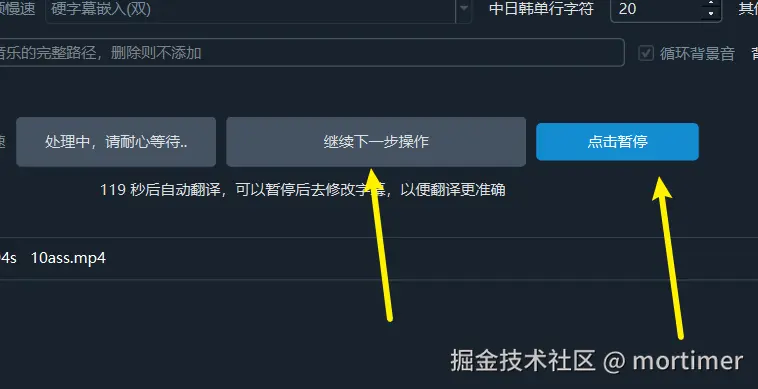
如果只翻译一个视频,软件会在生成字幕和翻译字幕后暂停, allowing for manual correction of the subtitles (例如修改错别字)。
如果选择了多个视频,翻译过程不会暂停,所有视频的字幕都会在右侧字幕区域显示,可能会显得比较混乱,但这不会影响最终的翻译结果。
查看结果
翻译完成后,点击进度条可以打开结果所在的文件夹。 翻译后的视频文件为 MP4 格式,其他文件是中间生成的素材文件 (例如 SRT 字幕文件、音频文件)。
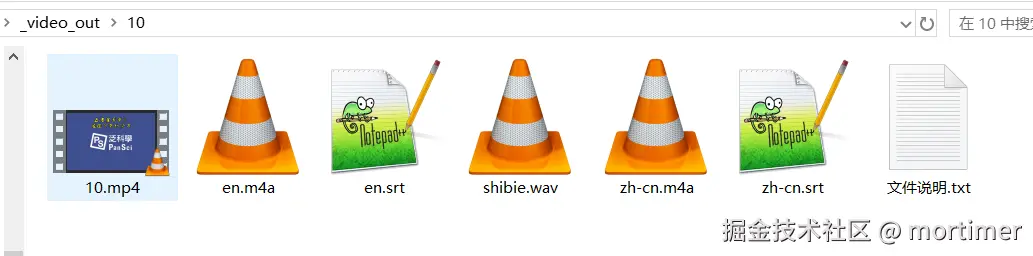
其他功能还有很多
例如
- 专门只用于将音视频转录为字幕
- 将srt字幕文件批量配音为音频
- 将srt字幕翻译为另一种语言的srt字幕
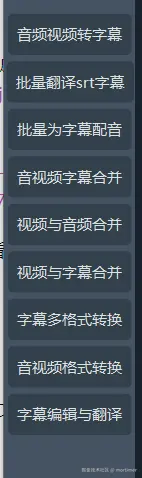
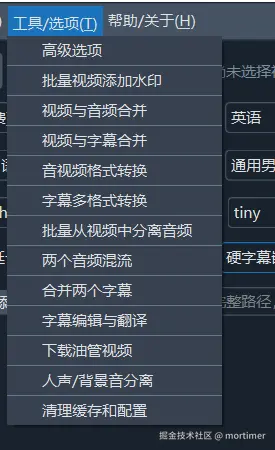
可根据需要使用
开源说明
本软件开源,开源地址 https://github.com/jianchang512/pyvideotrans
开源协议 GPL-V3: https://www.gnu.org/licenses/gpl-3.0.txt
软件官网: https://pyvideotrans.com
本软件免费下载、免费使用、无需登录无需注册,开发者也未在任何平台或授权任何人在任何平台销售。
软件内置多种免费开源方案,包括在线和本地,可免费使用。
同时软件也支持某些商业第三方api方案,例如 ChatGPT/腾讯翻译/字节火山,若需使用请自备相应账号和密钥等,需到对应第三方平台开通或购买,费用与本软件无关,软件只提供和第三方api的对接技术实现。