CosyVoice开源地址 https://github.com/FunAudioLLM/CosyVoice
CosyVoice-api开源地址 https://github.com/jianchang512/cosyvoice-api
支持 中文、英文、日语、韩语、粤语,对应语言代码分别是
zh|en|jp|ko|yue
在视频翻译软件中使用
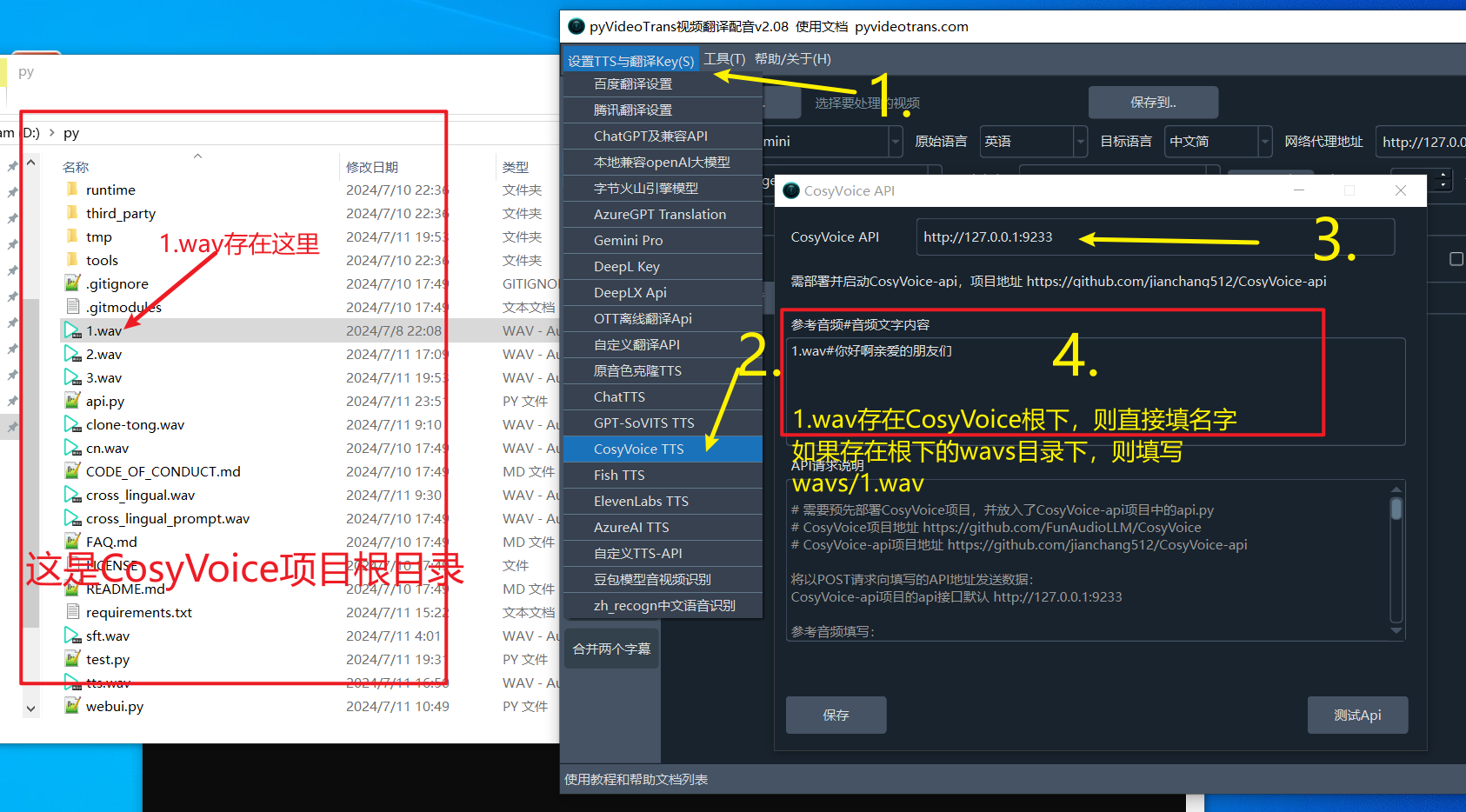
- 首先升级软件到2.08+
- 确保已部署CosyVoice项目,已将 CosyVoice-api中的api.py放入,并成功启动了 api.py(必须启动api服务才可在翻译软件中使用)。
- 打开视频翻译软件,左上角设置--CosyVoice:填写 api 地址,默认是
http://127.0.0.1:9233 - 填写参考音频和音频对应文字
参考音频填写:
每行都由#符号分割为两部分,第一部分是wav音频路径,第二部分是该音频对应的文字内容,可填写多行。
wav音频最佳时长5-15s,如果音频放在了CosyVoice项目的根路径下,即webui.py同目录下,这里直接填写名称即可.
如果放在了根目录下的wavs目录下,那么需要填写 wavs/音频名称.wav
参考音频填写示例:
1.wav#你好啊亲爱的朋友
wavs/2.wav#你好啊朋友们- 填写完毕后,主界面中配音渠道选择 CosyVoice, 角色选择对应的即可。其中 clone 角色是复制原视频中的音色
其他系统请先部署好 CosyVoice,具体部署方法如下
源码部署 CosyVoice 官方项目
部署采用 conda,也强烈建议这种方式,否则可能无法成功安装,遇到的问题会非常多,有些依赖无法Wndows上使用pip是无法成功安装的,例如
pynini
1. 下载并安装miniconda
miniconda是一个conda管理软件,在windows上安装很方便,和普通软件一样一路next即可完成。
下载地址 https://docs.anaconda.com/miniconda/
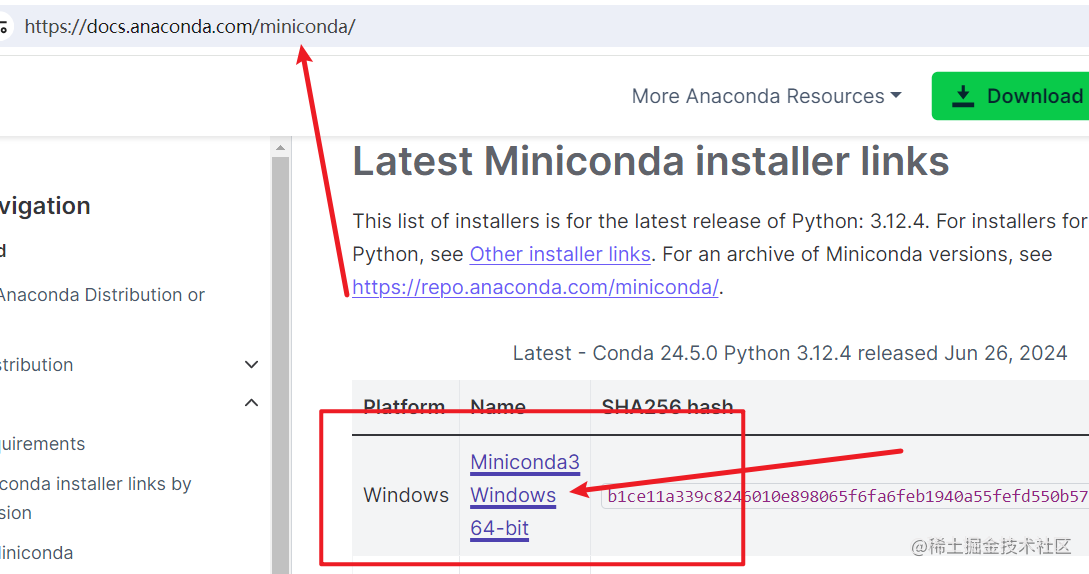
下载完毕后双击 exe 文件,
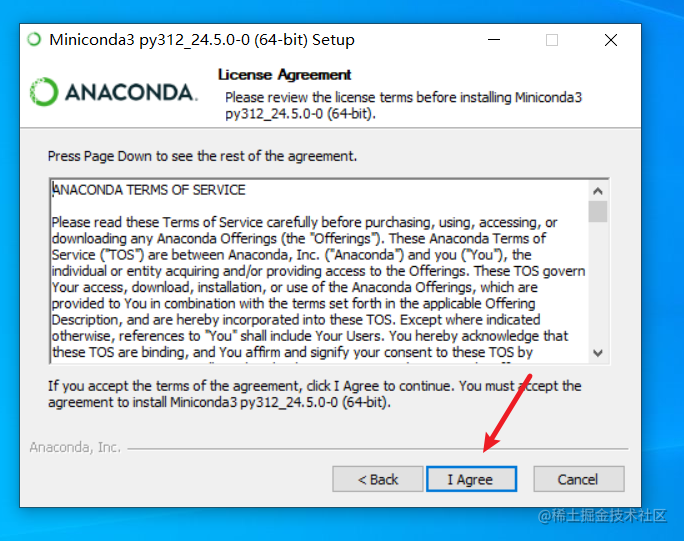
需要注意的只有一点,在下图这个界面,需要选中上面2个复选框,否则后边操作会有点麻烦。 第二个框选中的意思是“将conda命令加入系统环境变量”,如果不选中将无法直接使用 conda 简短命令。
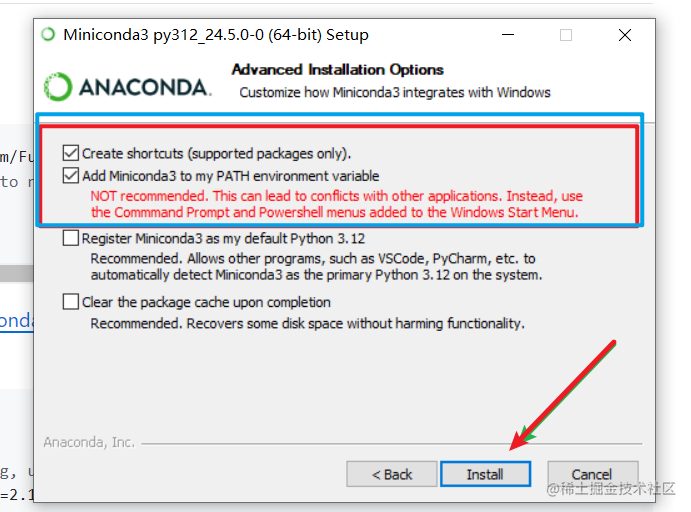
然后点击 “install” 等待完成后close即可
2. 下载 CosyVoice源代码
先创建一个空目录,比如在D盘下建立一个文件夹 D:/py,后续以此为例说明
打开CosyVoice开源地址 https://github.com/FunAudioLLM/CosyVoice
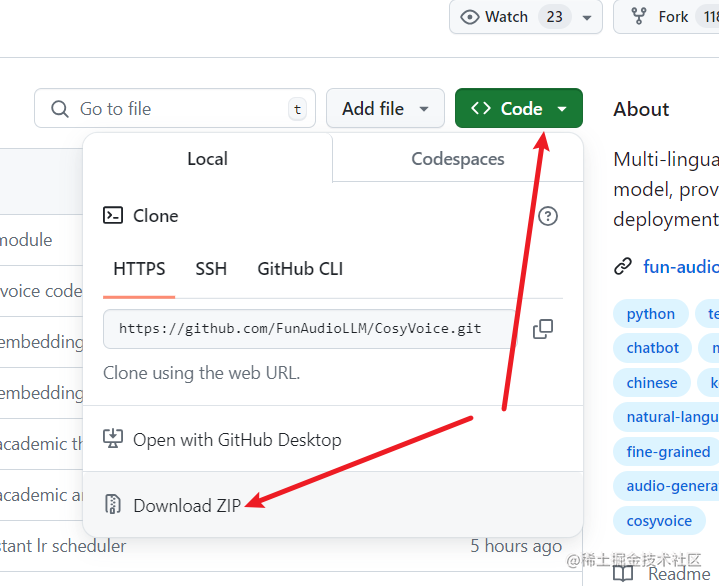
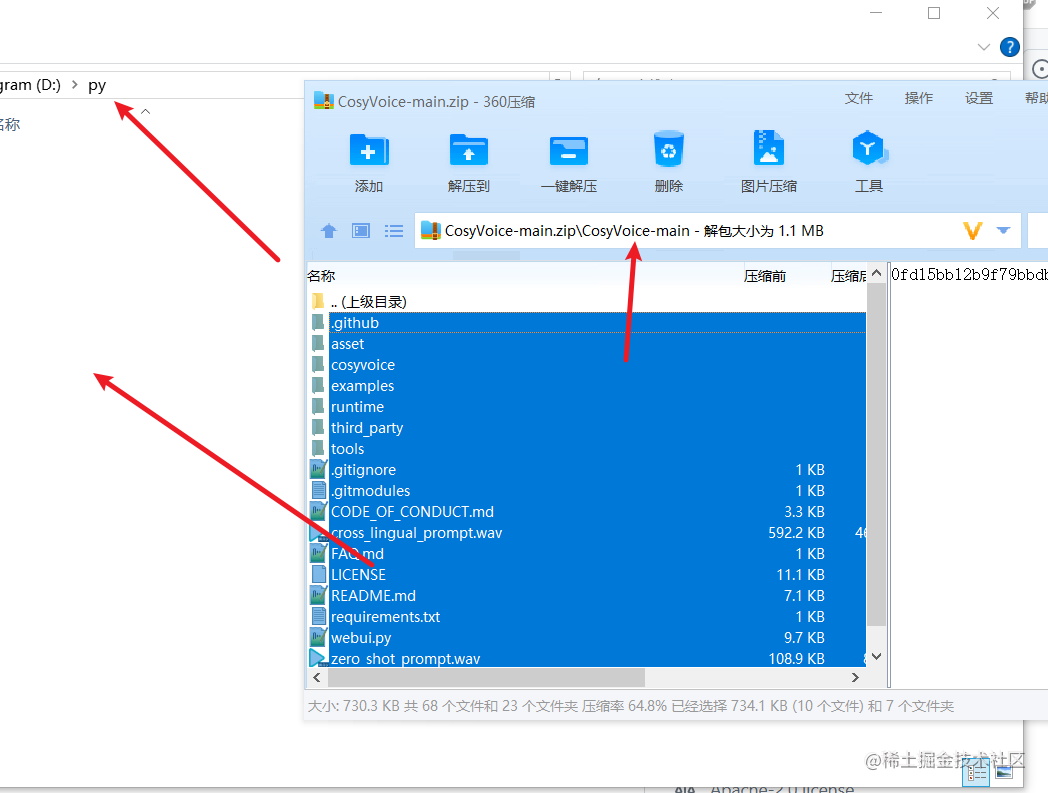
下载后解压,将其中CosyVoice-main目录内的所有文件复制到 D:/py中
3. 创建一个虚拟环境并激活
进入 D:/py 文件夹内,地址栏中输入cmd然后回车,会打开一个cmd黑窗口
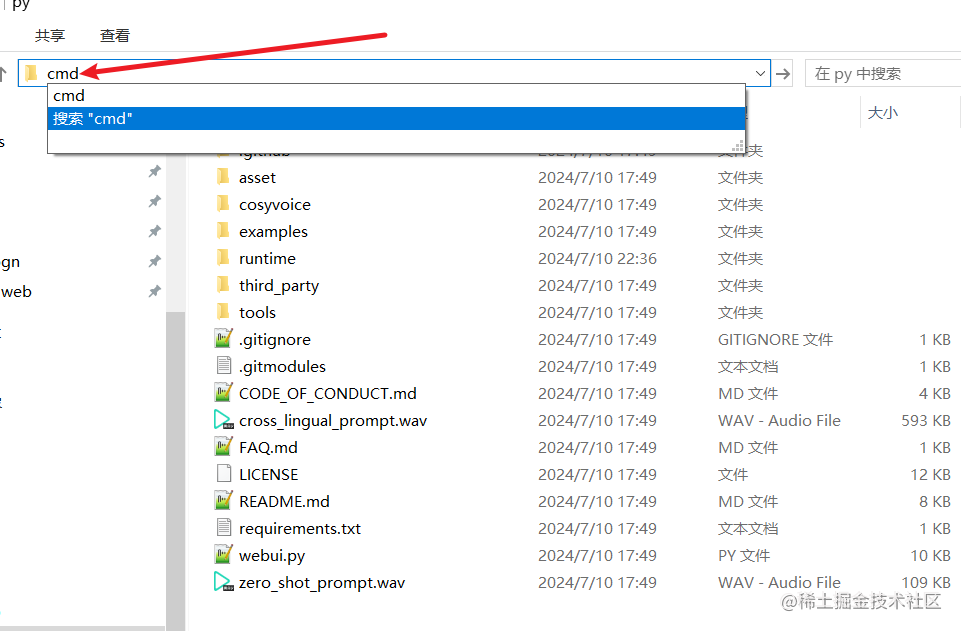
在该窗口中输入命令conda create -n cosyvoice python=3.10 然后回车,即创建一个名称为“cosyvoice”、python版本为“3.10”的虚拟环境,
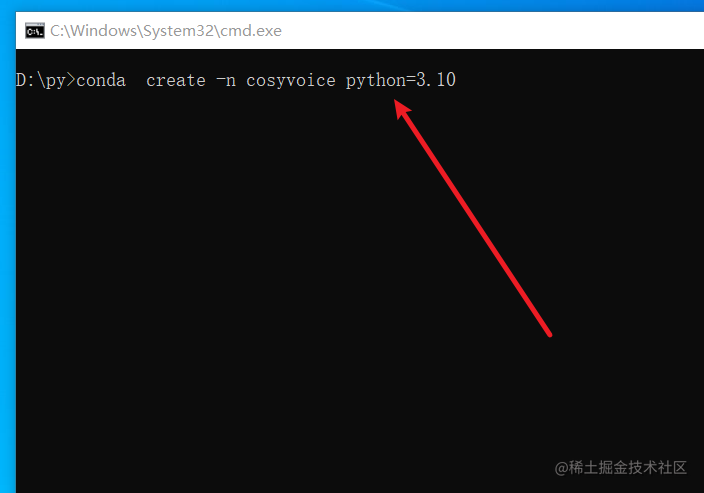
继续输入命令conda activate cosyvoice回车,即激活了该虚拟环境,只有激活后,才可继续进行安装、启动等操作,否则必然出错。
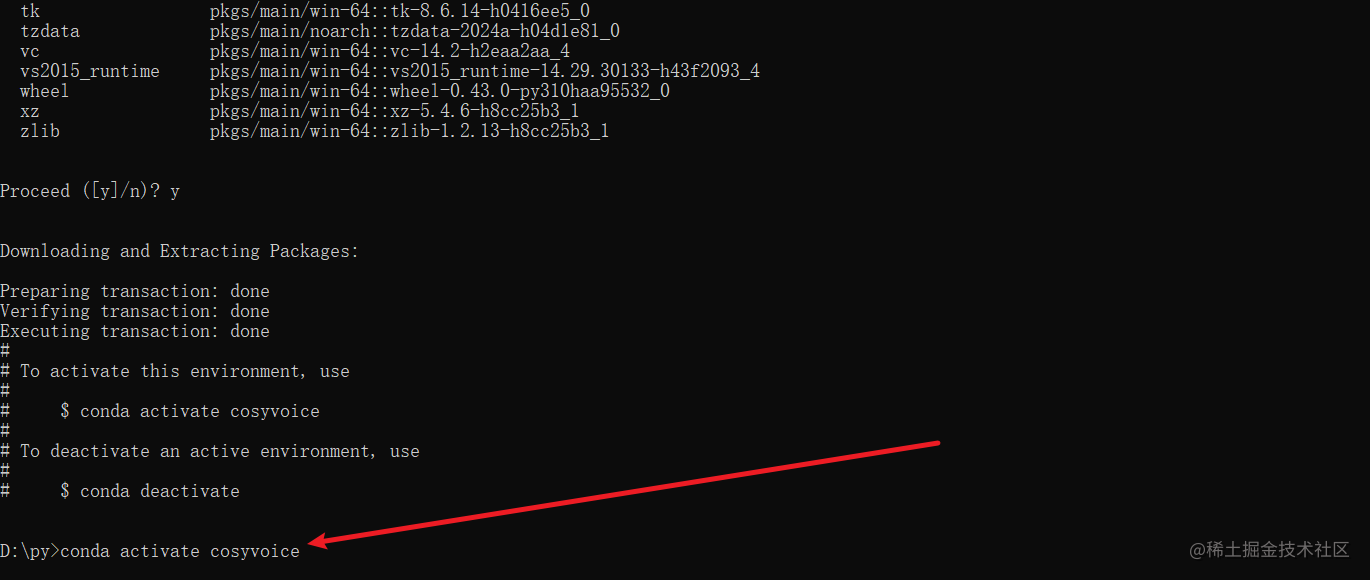
激活后的标志是命令行开头增加了“(cosyvoice)”字符

4. 安装 pynini 模块
该模块在windows下只有用conda命令才可安装,这也是开头建议windows上使用conda的原因。
继续在上面打开并激活环境的cmd窗口中输入命令 conda install -y -c conda-forge pynini==2.1.5 WeTextProcessing==1.0.3 回车
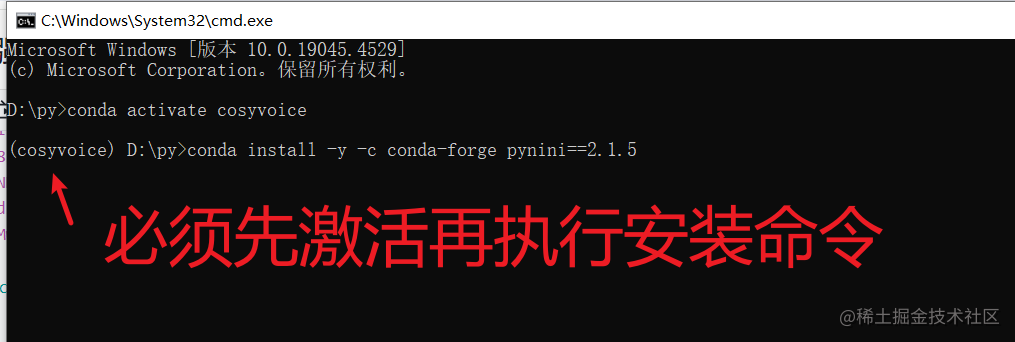
注意:安装中会出现一个要求输入确认的提示,此时输入y然后回车,如下图
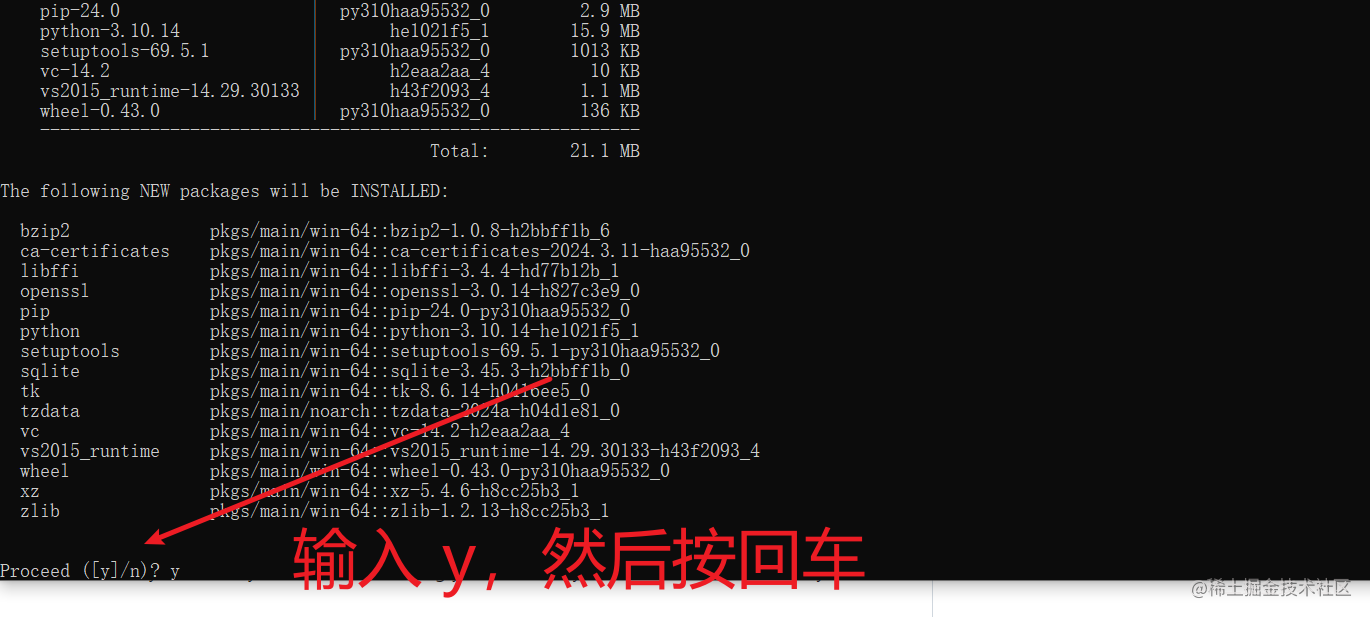
5. 安装其他一系列依赖,使用阿里镜像
打开
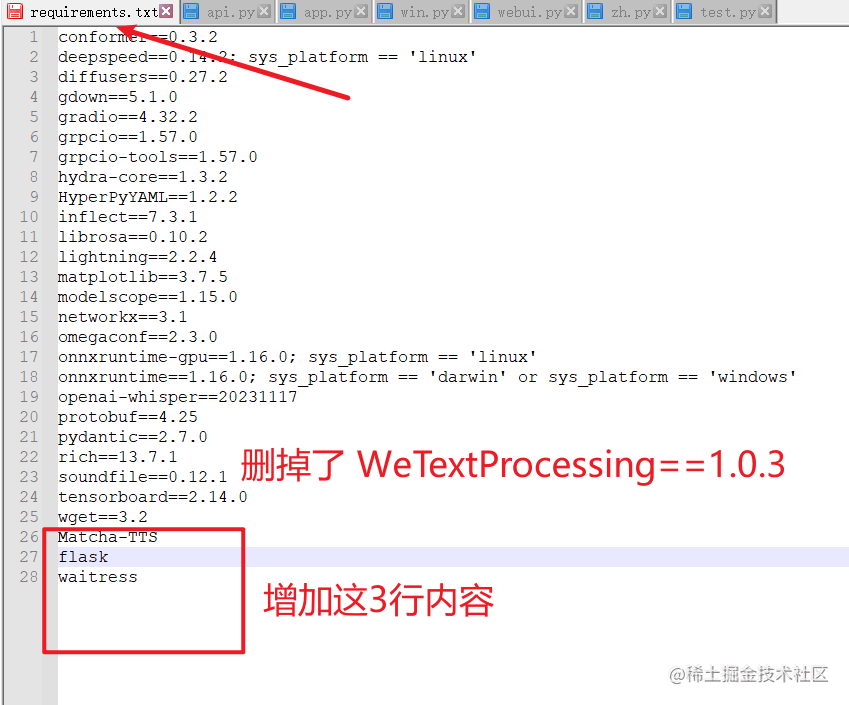
requirements.txt文件,删掉最后一行的WeTextProcessing==1.0.3,否则肯定是安装失败的,因为这个模块依赖pynini,而pynini在windows的pip下无法安装然后在 requirements.txt 里增加3行
Matcha-TTSflask和waitress
继续输入命令
pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/ --trusted-host=mirrors.aliyun.com
并回车,等待一段漫长的时间后,无意外即安装成功了。
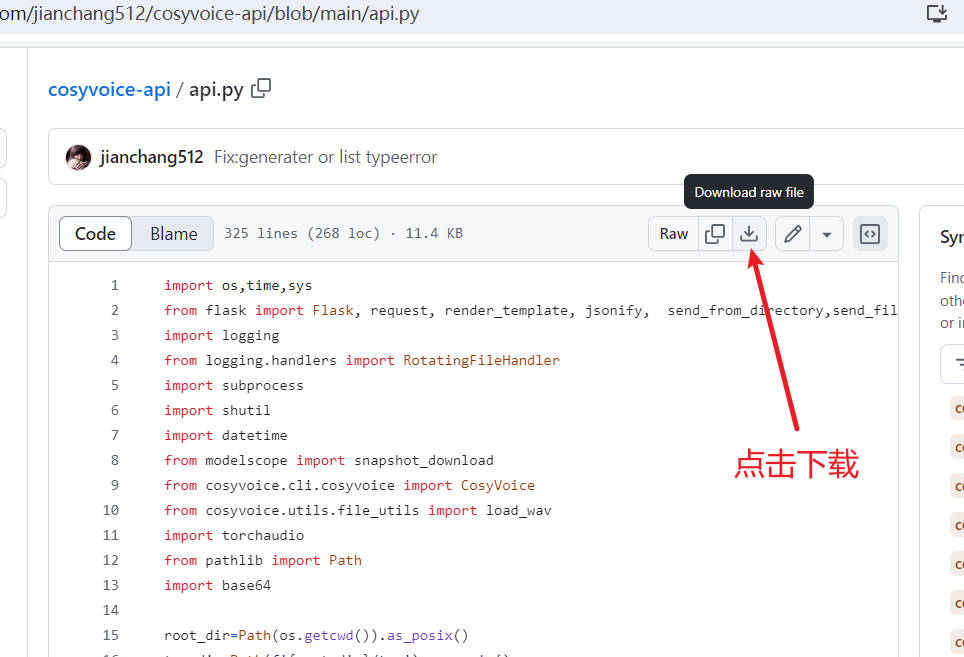
6. 下载 api.py 文件放在项目内
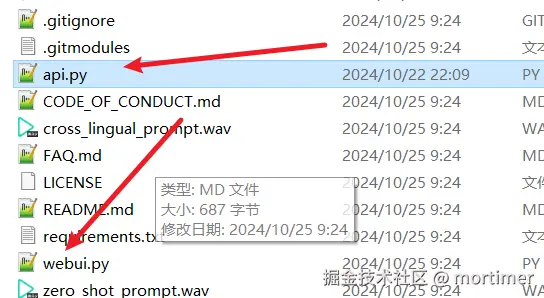
到这个地址 https://github.com/jianchang512/cosyvoice-api/blob/main/api.py 下载 api.py 文件,下载后和 webui.py放在一起
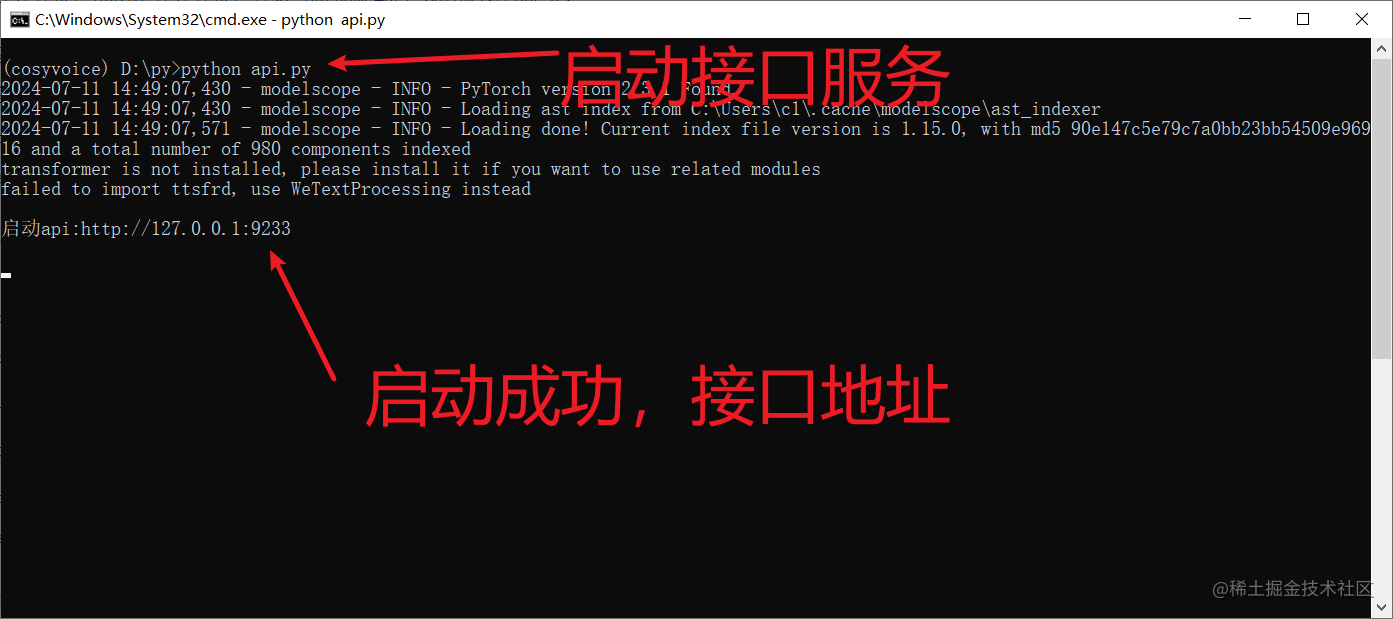
启动 API 服务
api接口地址为:
http://127.0.0.1:9233
输入命令回车执行 python api.py
API 接口列表
根据内置角色合成文字
接口地址: /tts
单纯将文字合成语音,不进行音色克隆
必须设置的参数:
text:需要合成语音的文字
role: '中文女', '中文男', '日语男', '粤语女', '英文女', '英文男', '韩语女' 选择一个
成功返回:wav音频数据
示例代码
data={
"text":"你好啊亲爱的朋友们",
"reference_audio":"10.wav"
}
response=requests.post(f'http://127.0.0.1:9933/tts',data=data,timeout=3600)同语言克隆音色合成
- 地址:/clone_eq
参考音频发音语言和需要合成的文字语言一致,例如参考音频是中文发音,同时需要根据该音频将中文文本合成为语音
- 必须设置参数:
text: 需要合成语音的文字
reference_audio:需要克隆音色的参考音频
reference_text:参考音频对应的文字内容 参考音频相对于 api.py 的路径,例如引用1.wav,该文件和api.py在同一文件夹内,则填写 1.wav
成功返回:wav数据
示例代码
data={
"text":"你好啊亲爱的朋友们。",
"reference_audio":"10.wav",
"reference_text":"希望你过的比我更好哟。"
}
response=requests.post(f'http://127.0.0.1:9933/tts',data=data,timeout=3600)不同语言音色克隆:
- 地址: /cone
参考音频发音语言和需要合成的文字语言不一致,例如需要根据中文发音的参考音频,将一段英文文本合成为语音。
- 必须设置参数:
text: 需要合成语音的文字
reference_audio:需要克隆音色的参考音频 参考音频相对于 api.py 的路径,例如引用1.wav,该文件和api.py在同一文件夹内,则填写 1.wav
成功返回:wav数据
示例代码
data={
"text":"親友からの誕生日プレゼントを遠くから受け取り、思いがけないサプライズと深い祝福に、私の心は甘い喜びで満たされた!。",
"reference_audio":"10.wav"
}
response=requests.post(f'http://127.0.0.1:9933/tts',data=data,timeout=3600)兼容openai tts
- 接口地址 /v1/audio/speech
- 请求方法 POST
- 请求类型 Content-Type: application/json
- 请求参数
input: 要合成的文字model: 固定 tts-1, 兼容openai参数,实际未使用speed: 语速,默认1.0reponse_format:返回格式,固定wav音频数据voice: 仅用于文字合成时,取其一 '中文女', '中文男', '日语男', '粤语女', '英文女', '英文男', '韩语女'
用于克隆时,填写引用的参考音频相对于 api.py 的路径,例如引用1.wav,该文件和api.py在同一文件夹内,则填写
1.wav
- 示例代码
from openai import OpenAI
client = OpenAI(api_key='12314', base_url='http://127.0.0.1:9933/v1')
with client.audio.speech.with_streaming_response.create(
model='tts-1',
voice='中文女',
input='你好啊,亲爱的朋友们',
speed=1.0
) as response:
with open('./test.wav', 'wb') as f:
for chunk in response.iter_bytes():
f.write(chunk)