F5-TTS-api
该项目源码地址 https://github.com/jianchang512/f5-tts-api
这是用于 F5-TTS 项目的api和webui
F5-TTS 是一款先进的文本转语音系统,它使用深度学习技术生成逼真、高质量的人声。只需短短10秒的音频样本,就能克隆出你的声音。F5-TTS 能够准确再现语音,并赋予其丰富的感情色彩。
原音色女儿国国王
克隆后音频
Windows集成包 (包含F5-TTS模型及运行环境)
123网盘下载 https://www.123684.com/s/03Sxjv-okTJ3
huggingface下载地址: https://huggingface.co/spaces/mortimerme/s4/resolve/main/f5-tts-api-v0.3.7z?download=true
适用系统: Windows 10/11 (下载后解压即可使用)
使用方法:
启动API服务: 双击 run-api.bat 文件,API地址为 http://127.0.0.1:5010/api。
必须启动api服务才可在翻译软件中使用
集成包默认使用CUDA 11.8版本。如果您有英伟达显卡并已配置好CUDA/cuDNN环境,系统会自动使用GPU加速。 如果想使用更高版本的cuda,比如12.4,请如下操作
进入到 api.py 所在文件夹,在文件夹地址栏输入
cmd后回车,然后在弹出的终端中分别执行以下命令
.\runtime\python -m pip uninstall -y torch torchaudio
.\runtime\python -m pip install torch torchaudio --index-url https://download.pytorch.org/whl/cu124
F5-TTS 的优势在于其高效性和高质量的语音输出。相比于需要较长音频样本的同类技术,F5-TTS 只需很短的音频就能生成高保真的语音,并能很好地表达情感,提升听感,这是许多现有技术难以做到的。
目前,F5-TTS支持英语和中文两种语言。
使用提示:代理/VPN
模型需要从 huggingface.co 网站下载。由于该网站在国内无法访问,请提前设置系统代理或全局代理,否则模型下载将会失败。
整合包已集成大部分所需模型,但可能会检测更新或下载其他依赖小模型,所以如果终端出现
HTTPSConnect错误时,仍需设置系统代理
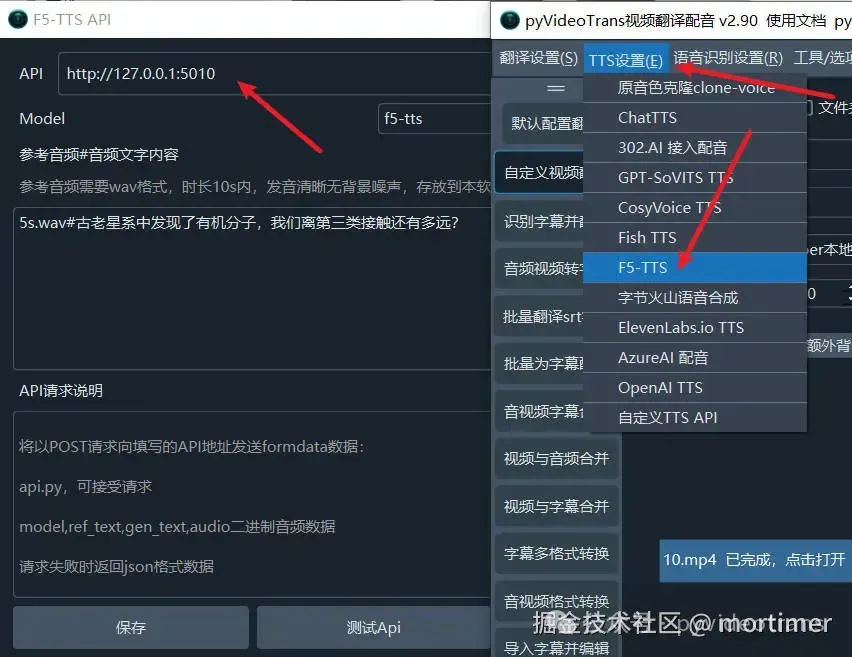
在视频翻译软件中使用
启动API服务。必须启动api服务才可在翻译软件中使用
打开视频翻译软件,找到TTS设置,选择F5-TTS,输入API地址(默认为 http://127.0.0.1:5010)。
输入参考音频和音频文本。
Model建议选择f5-tts 生成质量更好
在第三方整合包内使用 api.py
- 将 api.py 和 configs 文件夹复制到三方整合包内根目录内
- 查看三方整合包集成的 python.exe 路径,例如在 py311 文件夹内,那么在根目录下文件夹地址栏内输入
cmd回车,接着执行命令.\py311\python api.py,如果提示module flask not found,则先执行.\py311\python -m pip install waitress flask
源码部署F5-TTS官方项目后使用 api.py
- 将 api.py 和 configs 文件夹复制到项目文件夹内
- 安装模块
pip install flask waitress - 执行
python api.py
API 使用示例
import requests
res=requests.post('http://127.0.0.1:5010/api',data={
"ref_text": '这里填写 1.wav 中对应的文字内容',
"gen_text": '''这里填写要生成的文本。''',
"model": 'f5-tts'
},files={"audio":open('./1.wav','rb')})
if res.status_code!=200:
print(res.text)
exit()
with open("ceshi.wav",'wb') as f:
f.write(res.content)兼容openai tts接口
voice 参数必须用3个#号分割参考音频和参考音频对应的文本,例如
1.wav###你说四大皆空,却为何紧闭双眼,若你睁开眼睛看看我,我不相信你,两眼空空。 表示参考音频是 1.wav 和 api.py位于同一位置,1.wav里的文本内容是 "你说四大皆空,却为何紧闭双眼,若你睁开眼睛看看我,我不相信你,两眼空空。"
返回数据固定为wav音频数据
import requests
import json
import os
import base64
import struct
from openai import OpenAI
client = OpenAI(api_key='12314', base_url='http://127.0.0.1:5010/v1')
with client.audio.speech.with_streaming_response.create(
model='f5-tts',
voice='1.wav###你说四大皆空,却为何紧闭双眼,若你睁开眼睛看看我,我不相信你,两眼空空。',
input='你好啊,亲爱的朋友们',
speed=1.0
) as response:
with open('./test.wav', 'wb') as f:
for chunk in response.iter_bytes():
f.write(chunk)