为视频添加字幕,如今借助语音识别技术(ASR)已变得相当便捷。特别是 OpenAI 的 Whisper 系列模型,在语音转文字方面表现出色,让自动生成字幕成为可能。
然而,提取视频中已有的硬字幕(内嵌在视频画面中的字幕),仍然面临不少挑战。
视频本质上是由连续的图像帧组成。常见的视频帧率是 30fps(每秒 30 帧),这意味着 1 小时的视频就包含 108,000 张图像,对于高清视频,帧数则会更高。如此庞大的数据量对 OCR 处理能力提出了严峻的考验。
Google 的 Gemini-2.0-flash 模型不仅支持文本生成,还支持视频、图片的识别和处理,而且每日提供大量免费额度,可用来作为OCR工具。
国内的智谱 AI glm-4v-flash 模型不仅免费,也具备强大的图像理解能力,可以作为 OCR 工具使用。虽然目前仅支持中英文识别,但对于大多数场景已经足够。
基于Gemini和智谱AI 开发了一个硬字幕提取软件
下载地址 GVS 中英视频硬字幕提取软件(640MB)
百度网盘下载: https://pan.baidu.com/s/1SDKm5tWsr6dkajhsf8T5Ew?pwd=95i4
Github下载: https://github.com/jianchang512/stt/releases/download/0.0/GVS-v0.2-AI.7z
软件使用指南
以下是软件的使用步骤:
下载解压: 下载软件压缩包,解压后双击
app.exe即可运行。选择视频: 点击软件界面上方的按钮,选择需要提取字幕的视频文件,请确保视频中存在硬字幕。
选择字幕位置: 选择字幕在视频中的位置,默认是“底部”,您也可以选择“顶部”、“中间”或“全部”区域。
填写 API Key:
可填写 智谱AI 的 api key,这是国内免费的
也可填写 Gemini AI 的api key,每日有1500次免费调用额度,不过国内使用需要科学上网,以英文逗号分隔可填写多个key。
智谱 AI 平台可以免费注册并获取 API Key: https://bigmodel.cn/usercenter/proj-mgmt/apikeys
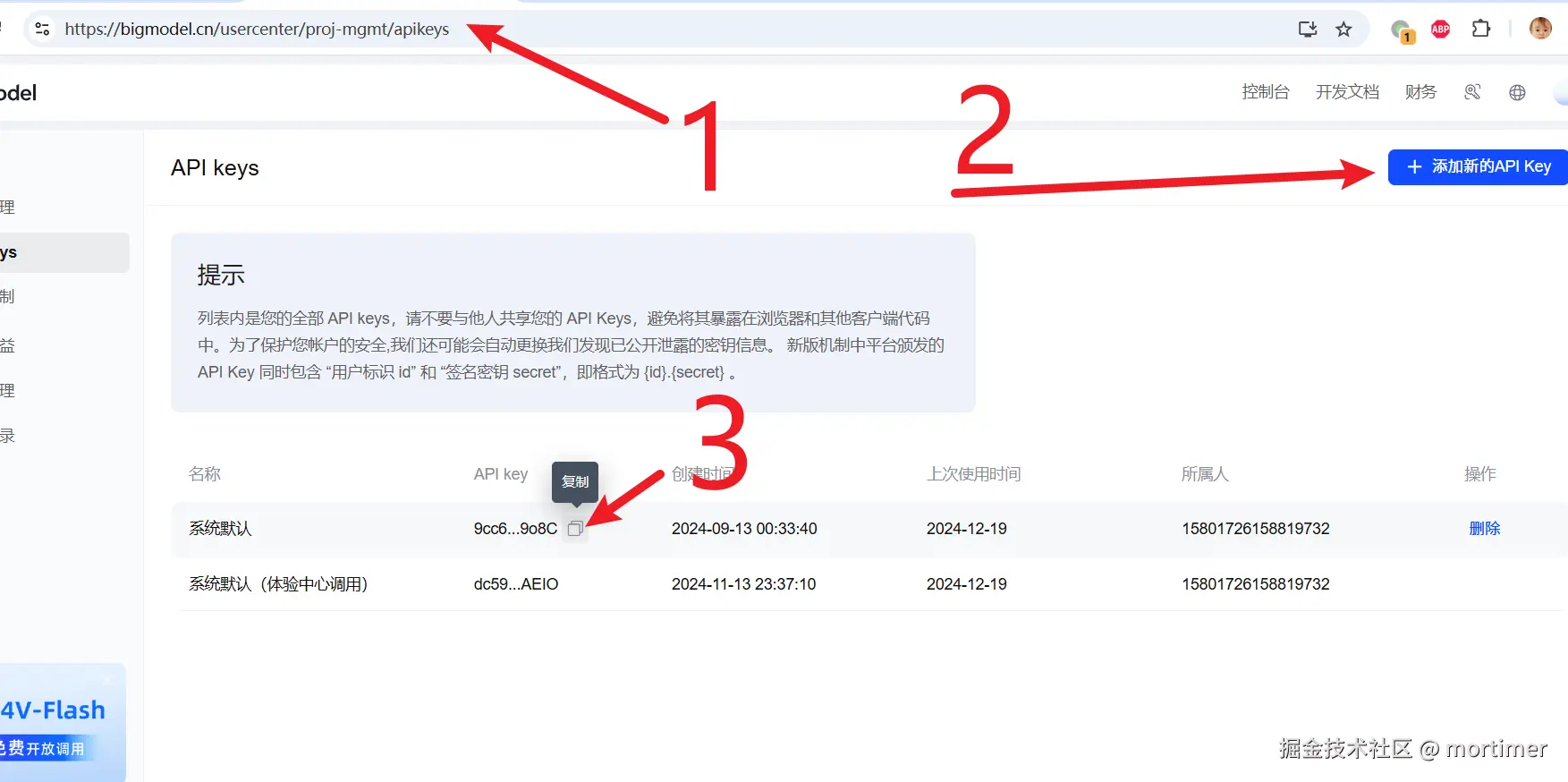
Gemini可去此页面获取 https://aistudio.google.com/app/apikey
选择模型: 智谱AI支持 GLM-4V-FLASH 免费模型。 GeminiAI支持
gemini-2.0-flash-exp和gemini-1.5-flash模型如果使用 GeminiAI,需填写代理ip和端口,或者在vpn软件中启用系统代理
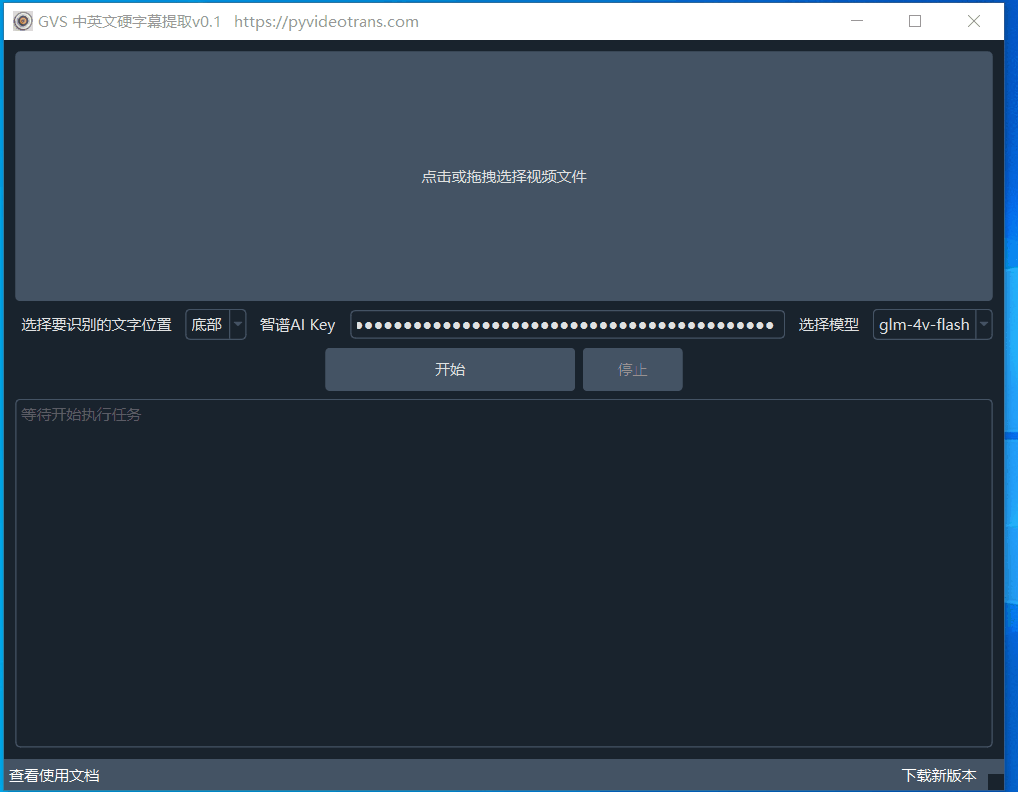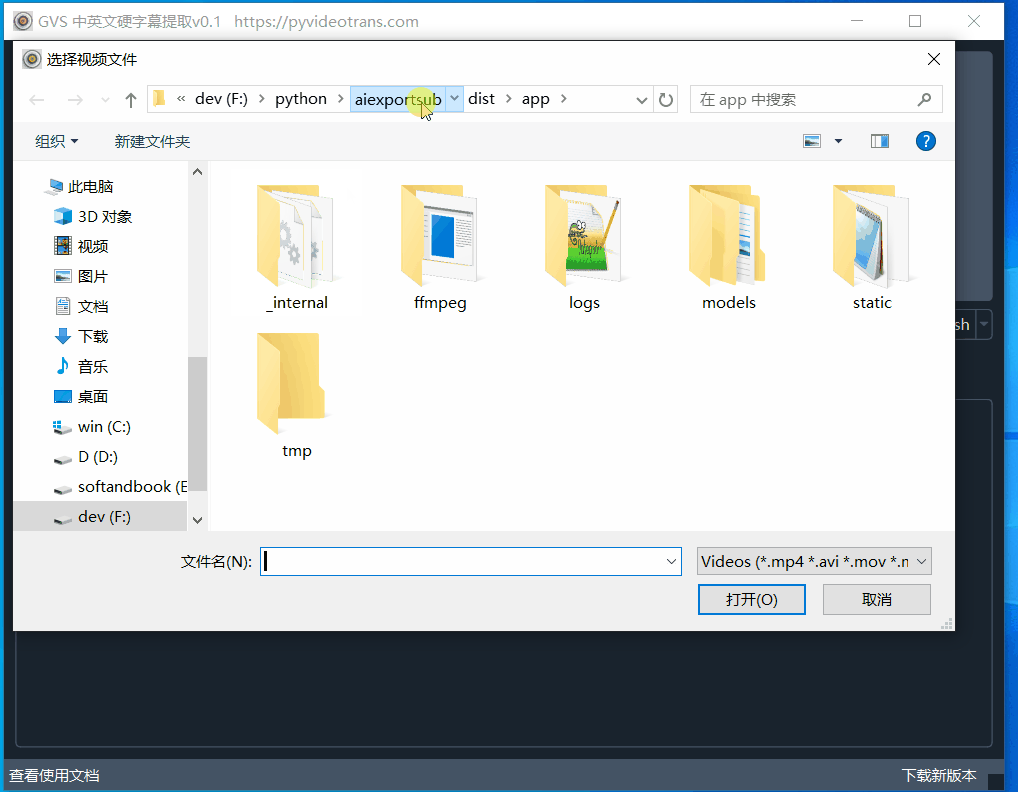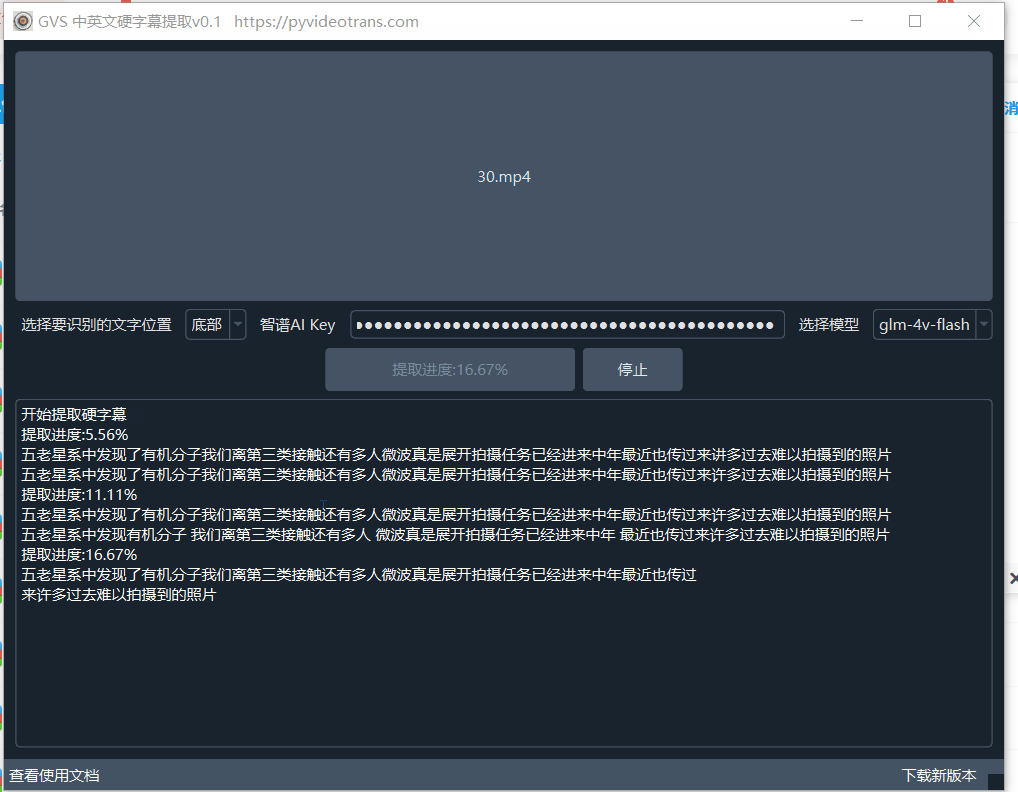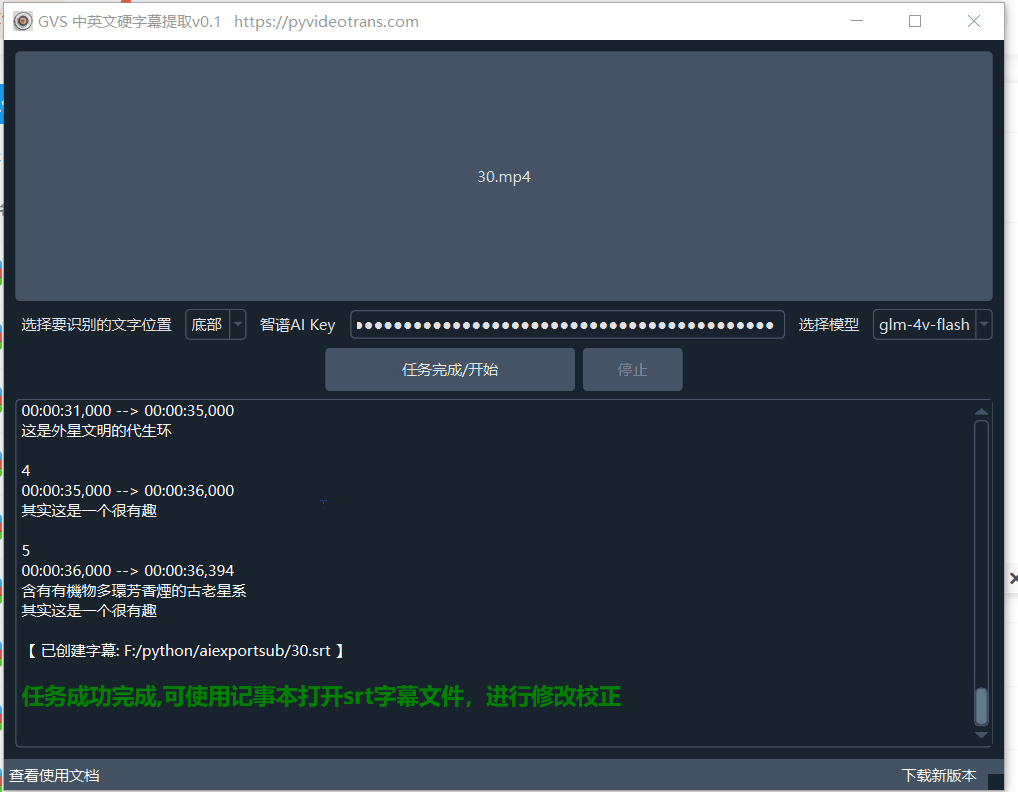
开始提取: 点击“开始”按钮,软件下方文本框会显示进度和日志信息。提取完成后,会在视频文件所在目录生成同名的 SRT 字幕文件。
技术原理
该软件提取硬字幕的核心步骤如下:
- 视频切帧: 首先,使用 FFmpeg 工具将视频按 1 秒间隔切分为图像帧。选择 1 秒间隔而非逐帧提取,一方面可以大幅减少需识别的图像数量,另一方面考虑到字幕通常持续时间不会低于 1 秒,过多的帧数也会增加去重的难度。
- OCR 识别: 将切分后的图像帧发送给 AI 模型,进行 OCR 识别,提取图像中的文字。
- 字幕去重: 由于连续的图像帧可能包含相同的字幕内容,为了避免重复,我们使用 sentence-transformers 模型计算当前识别出的字幕与前一句字幕的相似度。如果相似度超过 60%,则认为两条字幕内容相同,进行去重。
- 生成字幕文件: 最后,将去重后的字幕文本按照对应的时间戳进行拼接,并保存为 SRT 格式的字幕文件。