高级设置各个选项说明
在顶部菜单--工具/选项--高级选项 中可对一些参数进行自定义,以便实现更精细的控制。如下图。
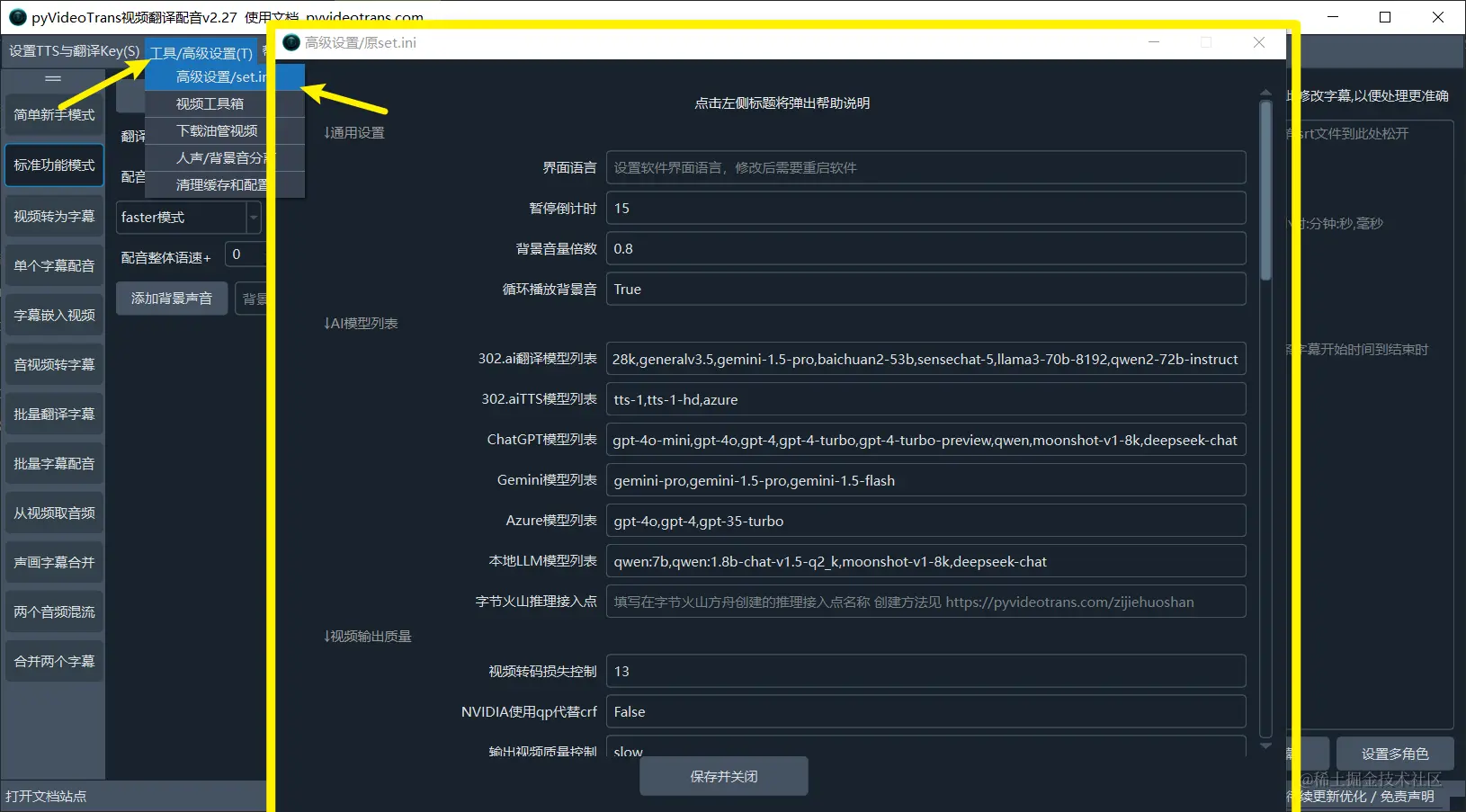
点击左侧文字标题,可弹出详细说明
界面语言: 设置软件界面语言,修改后需要重启软件,默认跟随操作系统,zh代表中文,en代表英文
暂停倒计时:当处理单个视频翻译时,在识别出字幕后以及字幕翻译后,均出暂停一段时间,可在此设置暂停的秒数
背景音量倍数:背景音频音量值为原本的倍数,比如填写0.8,则音量降低为原本的80%。
循环播放背景音:如果背景音频时长短于视频,是否重复播放背景音,true为循环播放,false为不循环。
302.ai翻译模型列表:填写302.ai用于翻译的模型名字,以英文逗号分隔
302.aiTTS模型列表:填写302.ai用于配音的模型名字,以英文逗号分隔
ChatGPT模型列表:可供选择的chatGPT模型,以英文逗号分隔
Gemini模型列表:Gemini模型列表,以英文逗号分隔
Azure模型列表:可供选择的模型,以英文逗号分隔
本地LLM模型列表:可供选择的模型,以英文逗号分隔
字节火山推理接入点:填写在字节火山方舟创建的推理接入点名称 创建方法见 https://pyvideotrans.com/zijiehuoshan
视频转码损失控制:视频转码时损失控制,0=损失最低,51=损失最大,默认13
NVIDIA使用qp代替crf:在 英伟达显卡上是否使用 qp 代替crf来控制视频质量损失,true=是,false=否
输出视频质量控制:用于控制输出视频质量和大小,越快质量越差
自定义ffmpeg命令参数:自定义ffmpeg命令参数, 将添加在倒数第二个位置上,例如 -bf 7 -b_ref_mode middle
264或265视频编码:填写264代表采用 libx264 编码,填写265代表采用libx265编码。264兼容性更好,265压缩比更大清晰度更高
音频最大加速倍数:音频最大加速倍数,默认3,即最大加速到原语速的3倍,需设置1-100的数字,比如3,代表最大加速3倍。用于控制配音后时长同原始时长对齐。
视频慢速倍数:视频慢速倍数:大于1的数,代表最大允许慢速多少倍,0或1代表不进行视频慢放,用于延长视频以便同配音和字幕对齐。
移除配音末尾空白:是否移除配音末尾的静音空白,true=移除,false=不移除。
移除字幕时长大于配音时长:是否移除原始字幕时长大于配音时长的静音,比如原时长5s,配音后3s,是否移除这2s静音,true=移除,false=不移除
移除2条字幕间的静音长度:移除2条字幕间的静音长度ms,比如100ms,即如果两条字幕间的间隔大于100ms时,将移除100ms, -1=完全移除
强制修改字幕时间轴:true=强制修改字幕时间轴以便匹配声音,false=不修改,保持原始字幕时间轴,不修改可能导致字幕和声音不匹配
启用VAD:faster-whisper字幕整体识别模式时启用VAD。true=启用,false=禁用。默认启用
最小静音片段:最小静音片段ms,默认250ms
语句最大持续秒数:语句最大持续秒数,默认6s。
VAD阈值:VAD阈值
VAD pad值:VAD pad值
均等分割时静音片段:均等分割模式下静音片段,默认10s
均等分割时片段时长:均等分割模式下每个片段时长秒数
faster和openai的模型列表:faster模式和openai模式下的模型名字列表,英文逗号分隔
CUDA数据类型:faster模式时cuda数据类型,int8=消耗资源少,速度快,精度低,float32=消耗资源多,速度慢,精度高,int8_float16=设备自选
whisper模型提示词:发送给whisper模型的提示词
faster-whisper cpu进程:faster模式下,字幕识别时,cpu进程数
faster-whisper工作进程:faster模式下,字幕识别时,同时工作进程数
字幕识别准确度控制1:字幕识别时精度调整,1-5,1=消耗显存最低,5=消耗显存最多
字幕识别准确度控制2:字幕识别时精度调整,1-5,1=消耗显存最低,5=消耗显存最多
faster-whisper温度控制:0=占用更少GPU资源但效果略差,1=占用更多GPU资源同时效果更好
上下文感知:true=占用更多GPU效果更好,false=占用更少GPU效果略差
硬字幕字体像素:硬字幕字体像素尺寸
硬字幕字体名字:硬字幕时字体名字
硬字幕文字颜色:设置字体的颜色,注意&H后的6个字符,每2个字母分别代表 BGR 颜色,即2位蓝色/2位绿色/2位红色,同同时常见的RGB色色颠倒的。
硬字幕文字边框颜色:设置字体边框颜色,注意&H后的6个字符,每2个字母分别代表 BGR 颜色,即2位蓝色/2位绿色/2位红色,同同时常见的RGB色色颠倒的。
硬字幕上移距离:字幕默认位于视频底部,此处可设置大于0的数值,代表字幕上移多少距离,注意最大不可大于(视频高度-20),也就是要保留至少20的高度用于显 示字幕,否则字幕将不可见
faster/openai-whisper识别后重新断句:如果选中,则识别后将使用nltk重新断句。
中日韩一行字符数:中日韩硬字幕时一行长度字符个数,多于这个将换行,默认20个字符,同时也用于重新断句时的依据
其他语言一行字符数:其他语言硬字幕时换行长度,多于这个字符数量将换行,默认54个字符,同时也用于重新断句时的依据
字幕繁体转为简体:强制将识别出的繁体字幕转为简体
同时翻译的字幕数:同时翻译的字幕条数,默认15
翻译出错重试数:翻译出错时的重试次数,默认2
翻译后暂停时间:每次翻译后暂停时间/秒,用于限制请求频率
同时配音字幕数:同时配音的字幕条数
AzureTTS批量行数:azureTTS一次配音行数,默认150
ChatTTS音色值:chatTTS 音色值