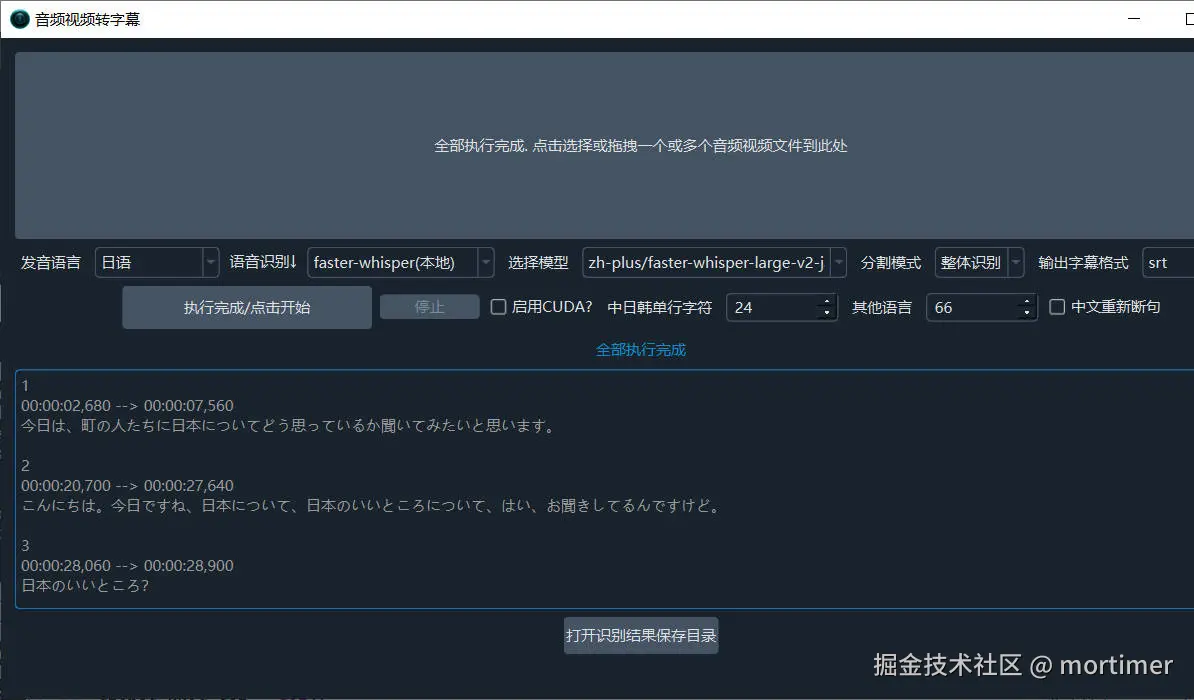
视频翻译软件通常自带多种语音识别渠道,用于将音视频中的人类说话声音转录为字幕文件。在中英文下,这些软件的效果尚可,但当用于日语、韩语、印尼语等小语种时,效果就不太理想了。
这是因为国外大型语言模型的训练素材主要以英语为主,中文的效果也不尽如人意。而国内模型的训练数据也基本集中在中英两种语言上,中文占比更高。
训练数据的缺乏导致模型效果不佳。幸运的是,Hugging Face 网站 https://huggingface.co 汇聚了海量微调模型,其中不乏专门针对小语种的微调模型,效果相当不错。
本文将介绍如何在视频翻译软件中使用 Hugging Face 的模型来识别小语种,以识别日语为例。
1. 科学上网
由于网络限制,国内无法直接访问 https://huggingface.co 网站。您需要自行配置网络环境,确保可以访问该网站。
访问后,您将看到 Hugging Face 网站的首页。
2. 进入 Models 目录
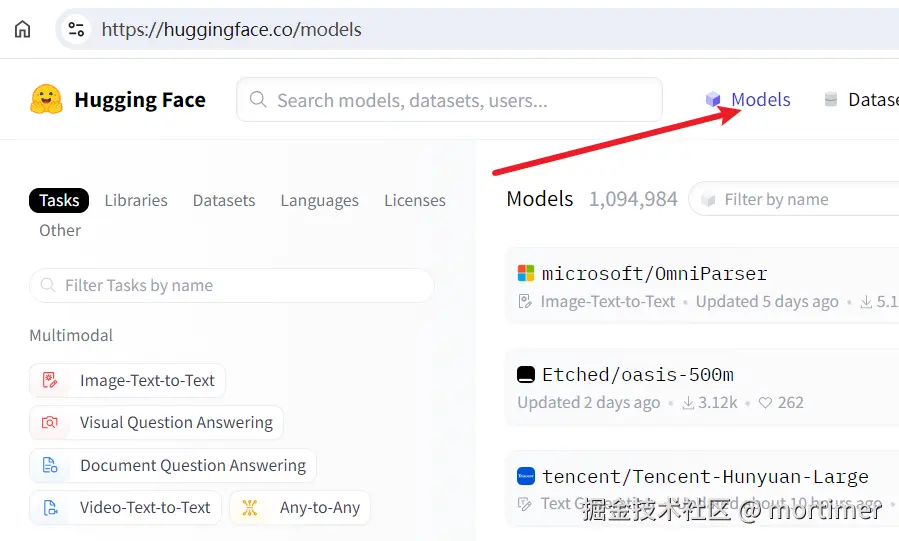
在左侧导航栏中点击 "Automatic Speech Recognition" 分类,右侧将显示所有语音识别模型。
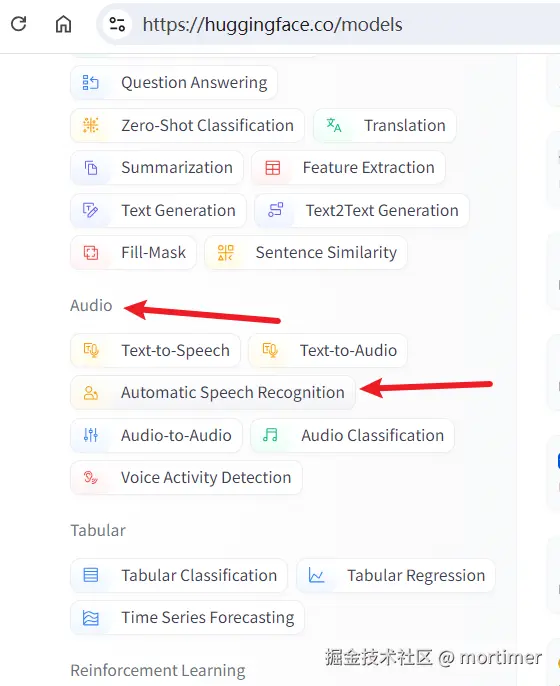
3. 查找兼容 faster-whisper 的模型
Hugging Face 网站目前拥有 20,384 个语音识别模型,但并非所有模型都适用于视频翻译软件。不同模型返回的数据格式不同,而视频翻译软件仅兼容 faster-whisper 类型的模型。
- 在搜索框中输入 "faster-whisper" 进行搜索。
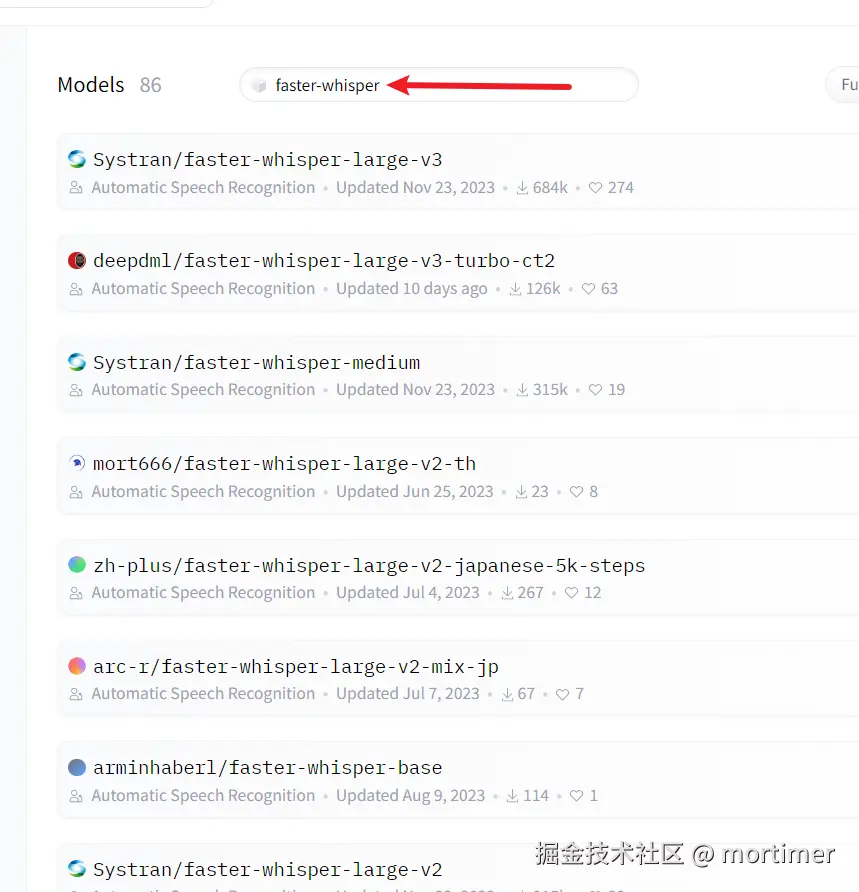
搜索结果中基本都是可以在视频翻译软件中使用的模型。
当然,有些模型虽然兼容 faster-whisper,但名字中不包含 "faster-whisper"。如何找到这些模型呢?
- 搜索语种名称,例如 "japanese",然后点击进入模型详情页面,查看模型介绍中是否说明兼容 faster-whisper。
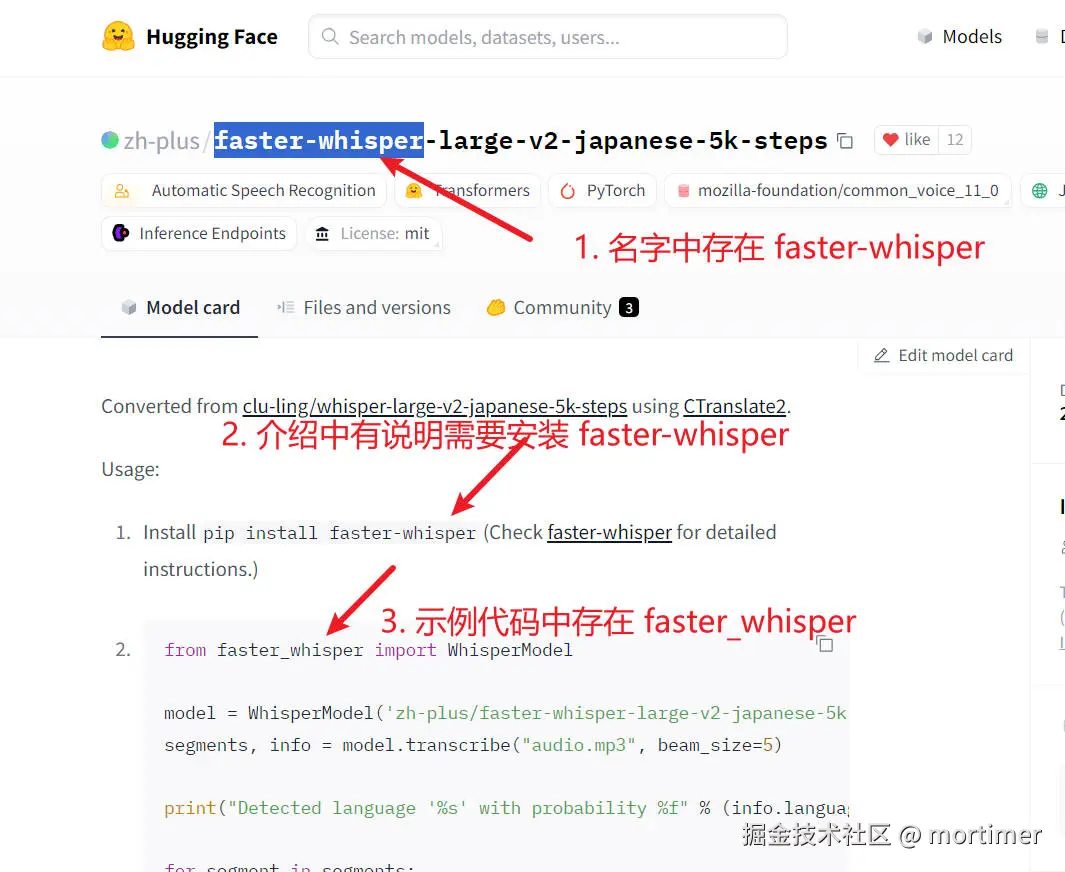
如果模型名称或介绍中没有明确提到 faster-whisper,则该模型不可用。即使出现了 "whisper" "whisper-large"等,也不可用,因为 "whisper" 用于兼容 openai-whisper 模式,而目前的视频翻译软件尚不支持,后续会否支持呢?视情况而定吧。
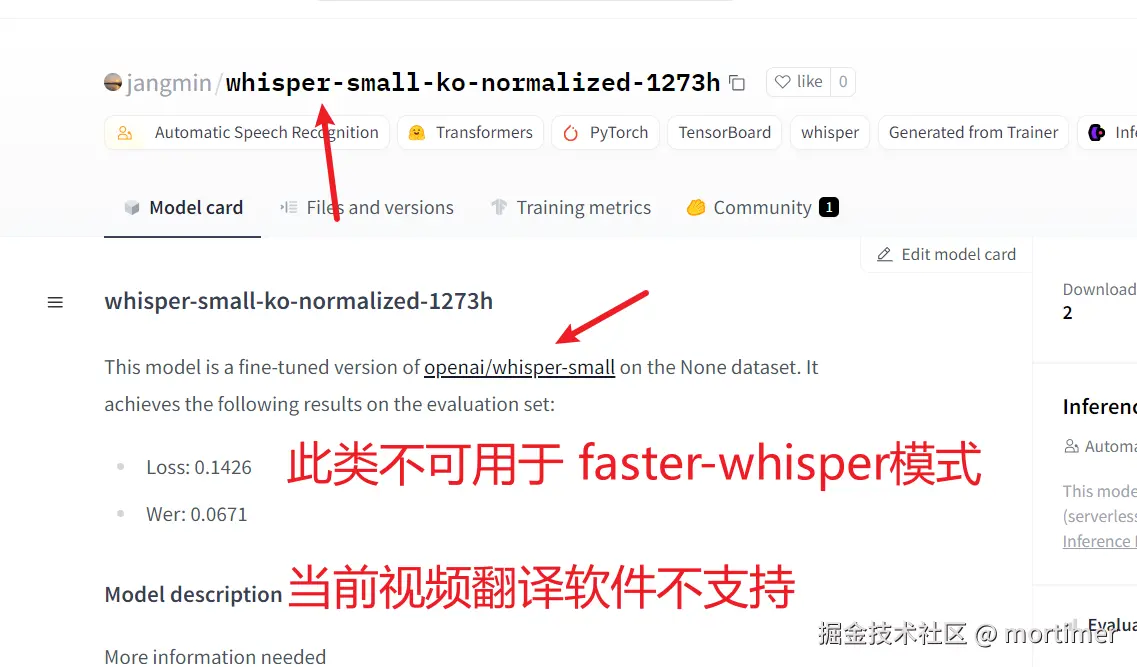
4. 复制模型 ID 到视频翻译软件
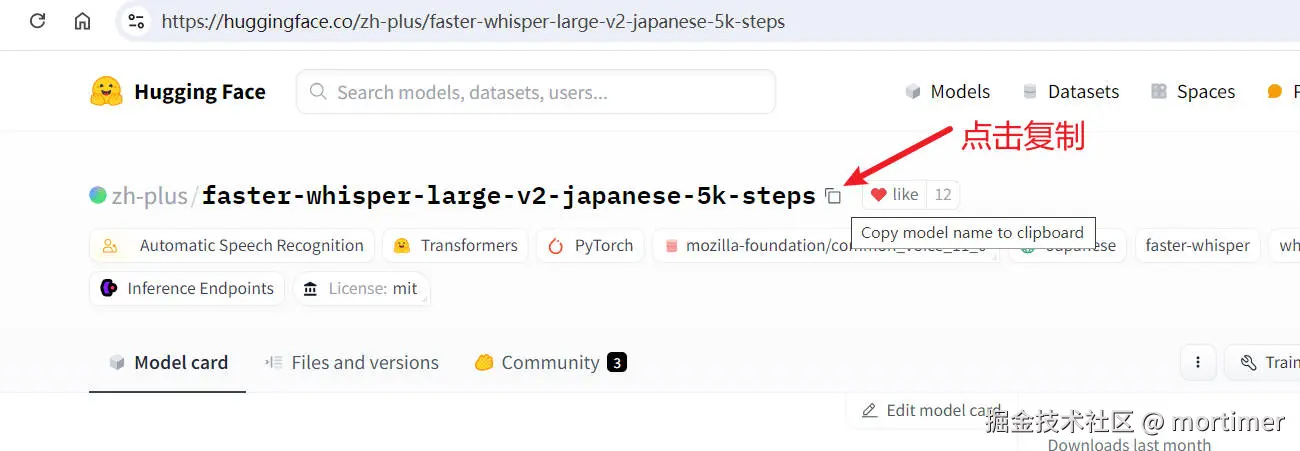
找到合适的模型后,复制模型 ID 并粘贴到视频翻译软件的 "菜单" -> "工具" -> "高级选项" -> "faster 和 openai 的模型列表" 中。
复制模型 ID。
粘贴到视频翻译软件中。
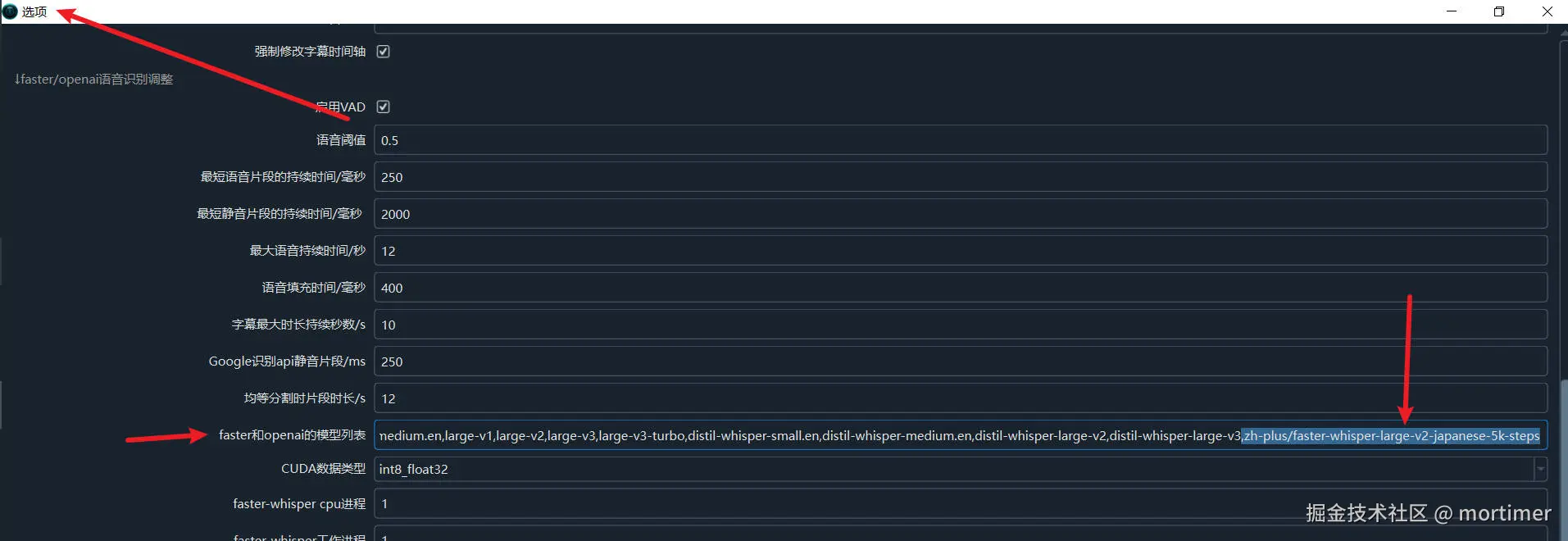
保存设置。
5. 选择 faster-whisper 模式
在语音识别渠道中,选择刚刚添加的模型。如果没有显示,请重启软件。
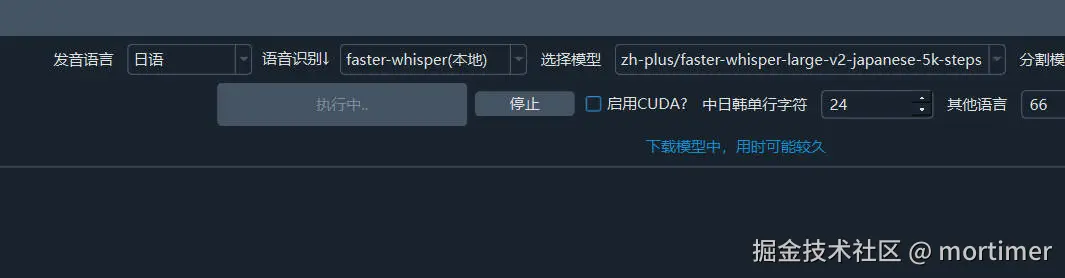
选择好模型和发音语音后,即可开始识别。
注意:必须设置代理,否则无法连接,会报错。可以尝试设置计算机全局代理或系统代理。如果仍然报错,请将代理 IP 和端口填写到主界面的 "网络代理" 文本框内。
网络代理的解释请查看 https://pyvideotrans.com/proxy
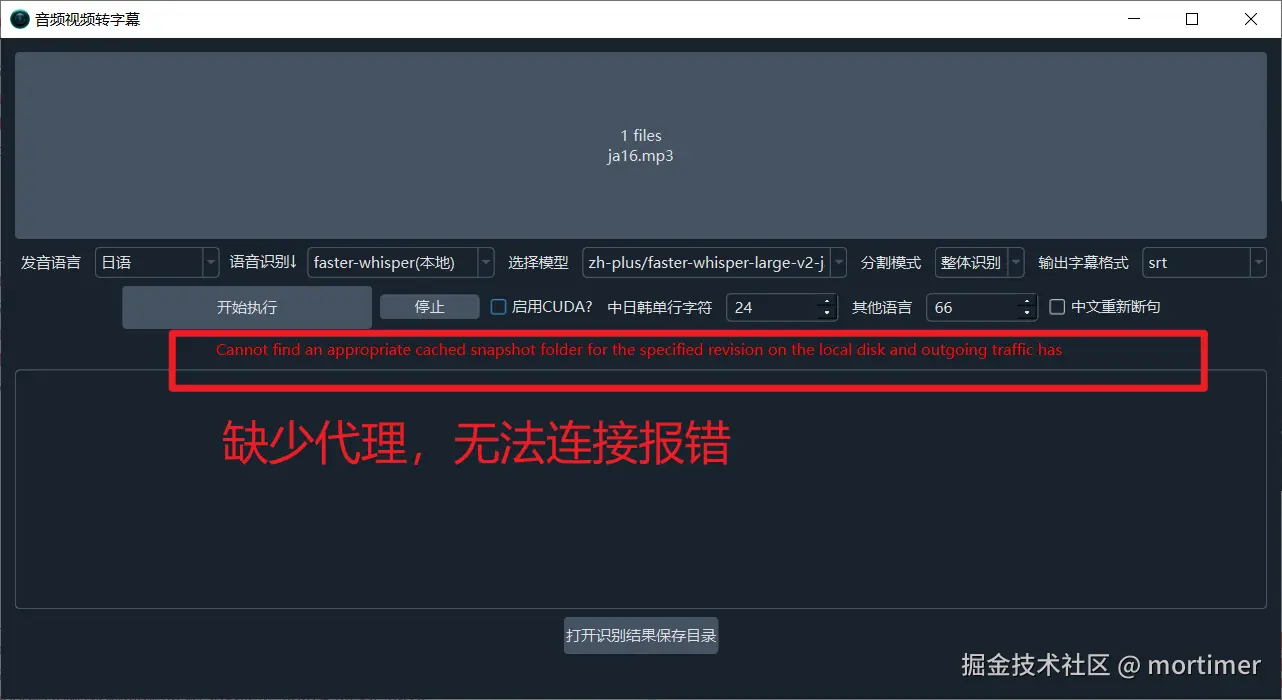
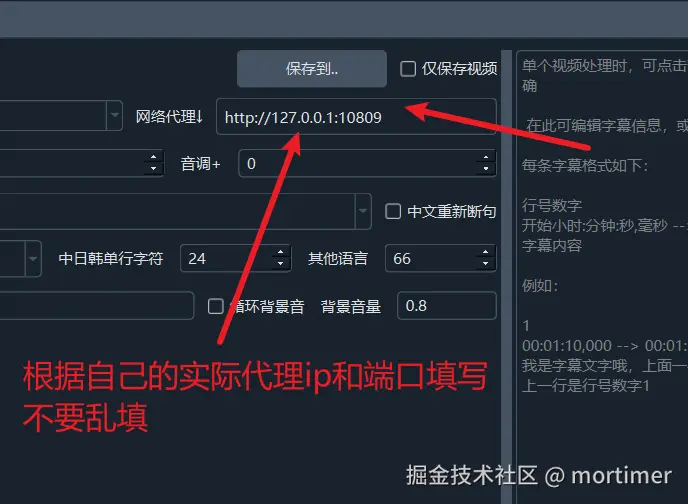
根据网络情况,下载过程可能需要较长时间,只要没有出现红色报错,请耐心等待。