FunASR中文识别:
FunASR是阿里开源的一套语音识别模型,在针对中文语音场景下效果好于whisper系列,视频翻译软件中已通过zh_recogn和 SenseVoice 项目使用http调用方式支持使用,只需要部署对应的 zh_recogn和SenseVoice整合包, 启动后,在视频翻译中 填写api地址即可使用。
但仍有不少用户对这个操作摸不着头脑,因此从 v2.97 版本起,已将此功能集成到视频翻译软件中,即无需额外再部署启动 zh_recogn 和 SenseVoice项目,直接在软件中选择 FunASR中文识别,就可以使用了。
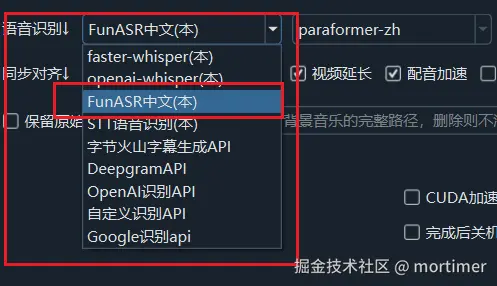
语音识别 中 选择 FunASR中文
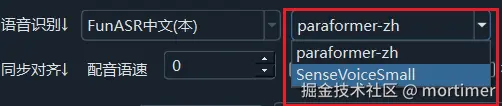
在语音识别中选择 FunASR中文识别 后,可选择使用 paraformer-zh 模型还是 SenseVoiceSmall 模型,建议选择前者,效果和速度都优于后者。
第一次使用FunASR中文识别在线下载模型
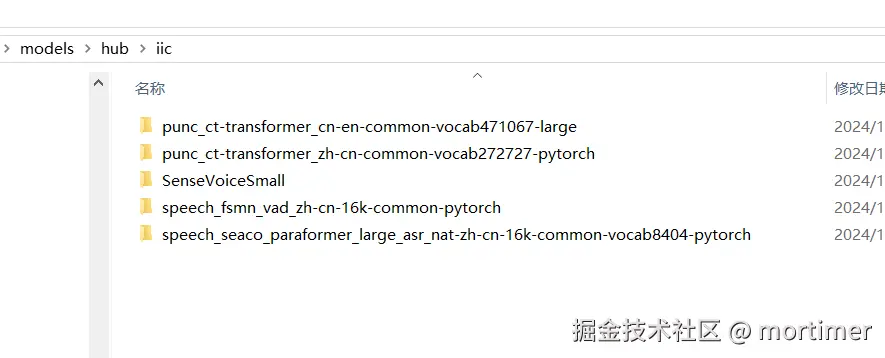
为避免软件包体积过大,FunASR 的模型并未集成在软件包内,第一次使用时会自动从 modelscope.cn 下载,下载后保存到软件目录下的models文件夹的hub内,根据网络情况可能需要几分钟到十几分钟甚至几十分钟不等,只要没有红色报错,就耐心等待下载完成。
提前单独下载FunASR模型文件
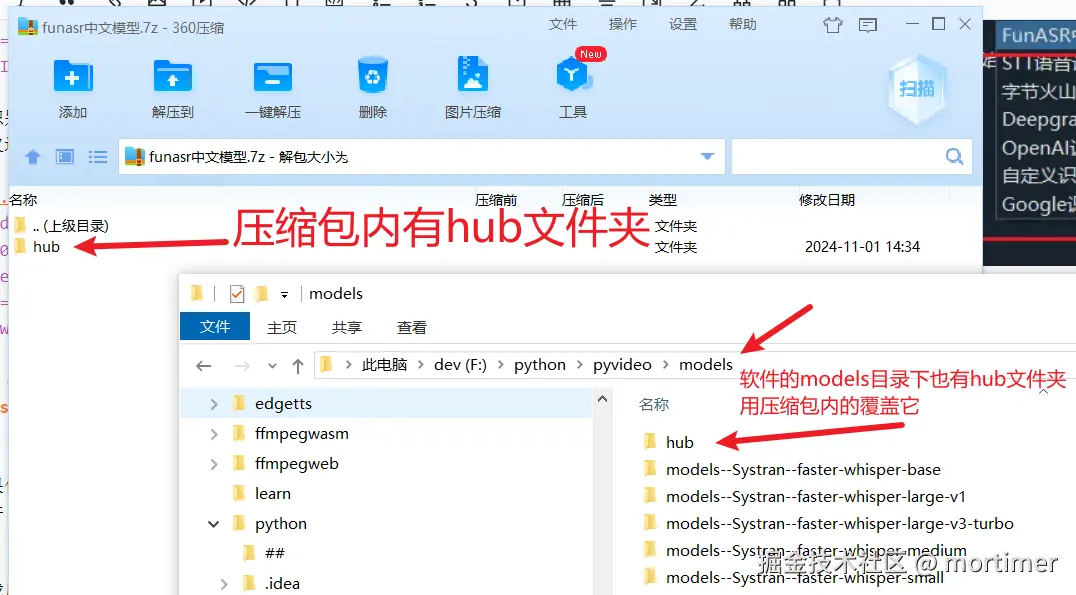
如果你的下载速度很慢,想提前下载模型文件,可单击该地址 https://pan.baidu.com/s/1HNvH_riUADtnZew8QjYS9w?pwd=jt5r ,下载后解压后,会看到在一个hub文件夹,将该文件夹复制到软件目录下的 models 文件夹内,覆盖其中的同名hub文件夹。
如图下载后,压缩包内存在hub文件夹,软件目录下的models目录内也存在一个hub文件夹