视频翻译软件的核心原理是:根据视频中的说话声音识别出文字,然后将文字翻译为目标语言文字,再将翻译后的文字进行配音,最后将配音、文字嵌入视频。
可以看到第一步就是从视频中的说话声识别出文字,识别精确度直接影响到后续翻译和配音。
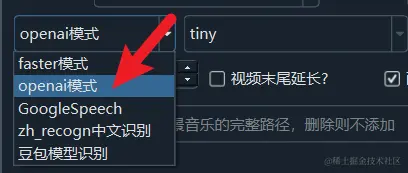
openai 模式
该模式是OpenAI官方开源的whisper模型,相比faster速度较慢,准确度一致。
右侧模型选择方式一样,从tiny到large-v3同样消耗计算机资源越来越多,精确度越来越高。
注意: faster模式和openai模式虽然模型名大多相同,但模型不通用,请到 https://pyvideotrans.com/model.html 下载用于 openai模式的模型
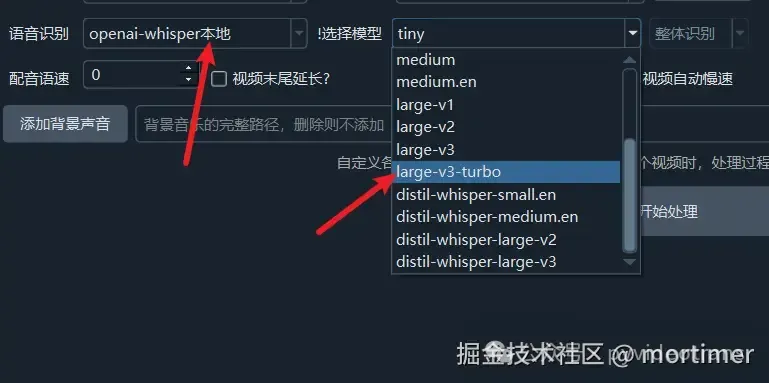
large-v3-turbo 模型
openai-whisper新近释出一个基于large-v3优化而来的模型large-v3-turbo,识别准确度同前者相近,而体积和资源消耗则大为降低,可作为large-v3的替代使用。
使用方法
软件升级到 v2.67版本 https://pyvideotrans.com
语音识别后下拉框选择 openai-whisper本地
模型后下拉框选择 large-v3-turbo
下载 large-v3-turbo.pt 文件到 软件目录下的 models 文件夹内