语音识别即音视频中的人类说话声转为文字,是视频翻译的第一步,也是决定后续配音、字幕质量的关键。 目前软件重点支持的也是能够本地离线识别的有faster-whisper本地和openai-whisper本地两种。
两者很相似,本质上 faster-whisper 是 openai-whisper 的再加工优化产物,识别精度基本一致但前者识别速度更快,相对的前者使用CUDA加速时对环境配置要求也更多。
faster-whisper本地识别模式
软件默认也推荐使用该模式,它的速度更快,效率更高。
该模式下的模型体积从小到大体积分别是 tiny -> base -> small -> medium -> large-v1 -> large-v3
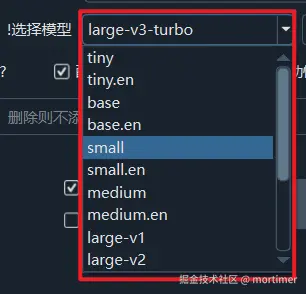
从前到后模型体积自 60MB 逐渐增加到 2.7G,所需要的内存、显存、CPU/GPU 消耗也逐渐增大,如果可用显存低于10G不建议使用large-v3 ,否则可能闪退卡死等
从 tiny 到 large-v3 随着体积和资源消耗的增加,相应的识别准确度也越来越高,tiny/base/small 这类属于微小模型,识别速度很快资源占用很少,但准确度很低;
medium属于中等模型,如果要识别中文发音的视频,推荐至少要使用大于等于medium的模型,否则效果不佳。
假如CPU足够强、内存足够大,即便不使用CUDA加速,也可选用 large-v1/v2 模型,精确度相比前面几个中小模型会提升很多,虽然识别速度会降低。
large-v3 占用资源较大,除非计算机够强悍,否则不推荐使用。建议使用 large-v3-turbo来代替它,两者精度一致,但large-v3-turbo又快占用资源又少。
模型名字以
.en结尾和以distil开头的,只可用于英语发音的视频,请勿用于其他语言视频。
openai-whisper本地识别模式
该模式下的模型和 faster-whisper 基本一致,也是从小体积到大体积分别是 tiny -> base -> small -> medium -> large-v1 -> large-v3 ,使用注意事项也一致,tiny/base/small 是微小模型,large-v1/v2/v3是大型模型。
总结选用方式
- 推荐优先考虑 faster-whisper本地模式,除非你想使用CUDA加速但始终报环境错误,可以使用openai-whisper本地模式
- 不论哪种模式,如果要识别中文发音的视频,建议至少选用medium模型,最小也得使用small,英语发音视频至少选用small。当然如果计算机资源充足,建议选用 large-v3-turbo.
.en结尾和distil开头的模型只可用于英语发音的视频