受益于AI技术的快速进步,曾经颇具挑战性的视频翻译如今变得更加易于实现,尽管效果可能尚未达到完美。
视频翻译较之文本翻译更为复杂,但核心依然是基于文字的翻译(尽管存在直接将声音转换成另一种语言声音的技术,但这种方法目前还不够成熟,实用性有限。)
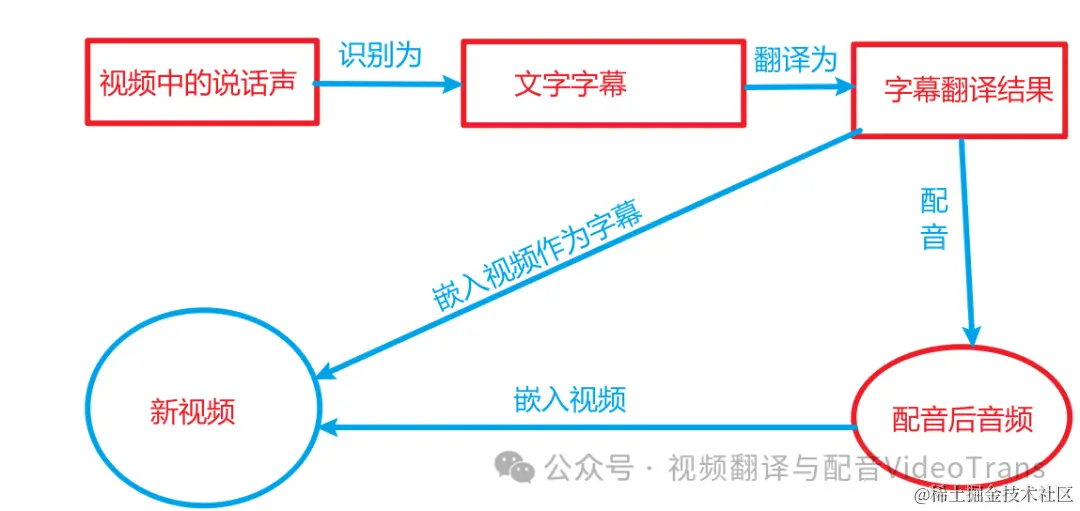
视频翻译的工作流程大致可以分为以下几个阶段:
语音识别:从视频中提取人声并转化为文字;
文字翻译:将提取的文字翻译成目标语言文字;
语音合成:根据翻译好的文字生成目标语言的语音;
同步调整:确保配音音频、字幕文件同视频画面内容同步;
嵌入处理:将翻译后的字幕和配音嵌入到视频中,生成新的视频文件。
详细探讨各个阶段:
语音识别
这一步骤的目标是将视频中的语音内容准确转换成文字,并附上时间戳。目前有多种实现方式,包括使用OpenAI的Whisper模型、阿里巴巴的FunASR系列模型,或者直接调用在线语音识别API,如百度语音识别。
选择模型时,可以根据需求从小型(tiny)到大型(large-v3)中选择,模型越大,识别精度越高。
文字翻译
得到文字后就可以进行翻译。要特别注意字幕翻译与普通文本翻译不同,字幕翻译时需要考虑时间戳的匹配问题。
使用传统翻译引擎(如百度翻译、腾讯翻译)时,应该只将字幕文字行传输进行翻译,避免传递 行号 时间戳行,以防止超出字符限制或改变字幕格式。
理想情况下,翻译后的字幕应与原字幕行数一致,无空白行。
但不同翻译引擎,尤其是AI翻译时,它会聪明的根据上下文合并行,特别是下一行只有孤零零的几个字符或一两个单词时,并且语义上和上一句是连贯的,它大概率会将此合并到上一行中。
虽然翻译结果更流畅优美,但也导致字幕无法和原字幕严格匹配,出现空白行。
合成配音
翻译完成后,可以根据翻译好的字幕生成配音。
目前,EdgeTTS 是一个几乎无限制且免费的配音渠道。通过逐行发送字幕至EdgeTTS,可以获得配音音频文件,之后将这些音频文件合并成一个完整的音频文件。
同步对齐调整
确保字幕、音频与视频同步是视频翻译的最大挑战。
不同语言的发音时长存在差异是必然的,这就导致出现同步问题,解决这一问题的策略包括加快音频播放速度或延长视频片段长度,以及利用字幕间的空白间隔进行调整,以达到最佳同步效果。
如果不做调整而是直接按原字幕时间戳嵌入,必然会发生字幕已经消失了,但人还在说话、或者视频中的人早已说完闭嘴了,然而音频仍在持续播放。
要解决这个问题,较为简单的方式有二种:
一是加速音频播放,强制在字幕时间区间内播放完毕,可达到同步效果,坏处是语速时快时慢,体验较差
二是慢速播放该字幕区间的视频片段,即延长该视频片段直到长度匹配新配音长度,也可以达到同步,坏处是画面会出现类卡顿效果
可以同时使用两种方式,即音频加速的同时,视频片段延长,既防止音频加速过快,也防止视频延长过多。
根据视频实际情况,还可利用2条字幕之间的空白间隔片段,先尝试不音频加速的情况下,音频在字幕指定区间内加速空白间隔时间内,能否正常播放完毕,如果可以,则不必加速,这样效果会更佳,当然坏处是视频画面中已说完,实际音频还在播放。
合成输出
完成以上步骤后,将翻译后的字幕和配音嵌入原视频,可以使用ffmpeg等工具轻松实现。最终生成的视频文件即完成了翻译过程。
ffmpeg -y -i 原视频.mp4 -i 配音音频.m4a -c:v libx264 -c:a aac -vf subtitles=字幕.srt out.mp4
难以解决的问题:多说话人识别
说话人角色识别,即按视频不同人物角色合成不同的配音,这涉及到说话人识别,而且需要预先指定有几个说话人角色,对于普通一二人对话角色勉强合适,但对于大多视频来说,难以提前确定几个说话人,最终合成的效果也很差,因此暂未考虑这块。
小结
以上只是简单的流程原理,实际上要取得好的翻译效果,还有许多注意点,比如原始视频输入格式的预先处理(mov/mp4/avi/mkv)、将视频拆分为音频和无声视频、音频中的人声背景声分离,字幕翻译时为加快速度批量翻译的结果处理、字幕出现空白行时的再拆分,双字幕生成和嵌入等等。
通过这一系列的步骤,视频翻译任务得以顺利完成,将视频内容无缝转换成目标语言,尽管过程中可能会遇到一些技术挑战,但随着技术的不断进步和优化,未来视频翻译的质量和效率都有望得到进一步提升。