ChatTTS火出圈了,然而文档语焉不详,尤其在语气、韵律、发音人具体控制方面,经过反复实测和踩坑,终于明白一点,记录如下。
ui界面代码开源地址 https://github.com/jianchang512/chattts-ui
文本中可用的控制符号
可在原始待合成文本中穿插控制符号,目前可控制的有 笑声、停顿 这2种。
[laugh] 代表笑声
[uv_break] 代表停顿
如下示例文本
text="你好啊[uv_break]朋友们,听说今天是个好日子,难道[uv_break]不是吗[laugh]?"在实际合成中,[laugh] 将被笑声替代,[uv_break] 处将加入停顿。
对于笑声 停顿的强度,可通过参数 params_refine_text中传递 prompt 控制。
laugh_(0-2) 可选值: laugh_0 laugh_1 laugh_2 笑声愈加强烈/或?
break_(0-7) 可选值: break_0 break_1 break_2 break_3 break_4 break_5 break_6 break_7 停顿依次更加明显/或?。
代码
chat.infer([text],params_refine_text={"prompt":'[oral_2][laugh_0][break_6]'})
chat.infer([text],params_refine_text={"prompt":'[oral_2][laugh_2][break_4]'})不过实际测试发现, [break_0] 到 [break_7] 区别不明显,[laugh_0]到[laugh_2]同样无明显差别
跳过 refine text 阶段
实际合成时会重新整理(refine text)插入控制符,比如上方示例文本,最终会被整理为
你 好 啊 [uv_break] 啊 [uv_break] 嗯 [uv_break] 朋 友 们 , 听 说 今 天 是 个 好 日 子 , 难 道 [uv_break] 嗯 [uv_break] 不 是 吗 [laugh] ? [uv_break]
可以看到,控制符同自己标注的并不一致,实际合成效果可能出现不该有的停顿、噪声、笑声等,那么如何强制按照实际去合成呢?
将 skip_refine_text 参数设为 True,跳过 refine text 阶段即可
chat.infer([text],skip_refine_text=True,params_refine_text={"prompt":'[oral_2][laugh_0][break_6]'})
固定发音人音色
默认每次合成都随机调用不同音色,这点非常不友好,而且也没有音色选择的具体说明。
若要简单固定发音角色,首先需要手动设置一个随机数种子,不同的种子会产生不同的音色
torch.manual_seed(2222)
然后获取一个随机说话人
rand_spk = chat.sample_random_speaker()
再通过 params_infer_code 参数传递
chat.infer([text], use_decoder=True,params_infer_code={'spk_emb': rand_spk})
经测试,2222 7869 6653 是男性音色,3333 4099 5099 是女性角色,更多角色可以自行调整不同的种子数测试。
语速控制
通过 chat.infer的 params_infer_code 参数中设置 prompt可控制语速
chat.infer([text], use_decoder=True,params_infer_code={'spk_emb': rand_spk,'prompt':'[speed_5]'})
速度值未有列明可选范围,源码中默认为 speed_5,但测试speed_0 speed_7 均未发现明显不同
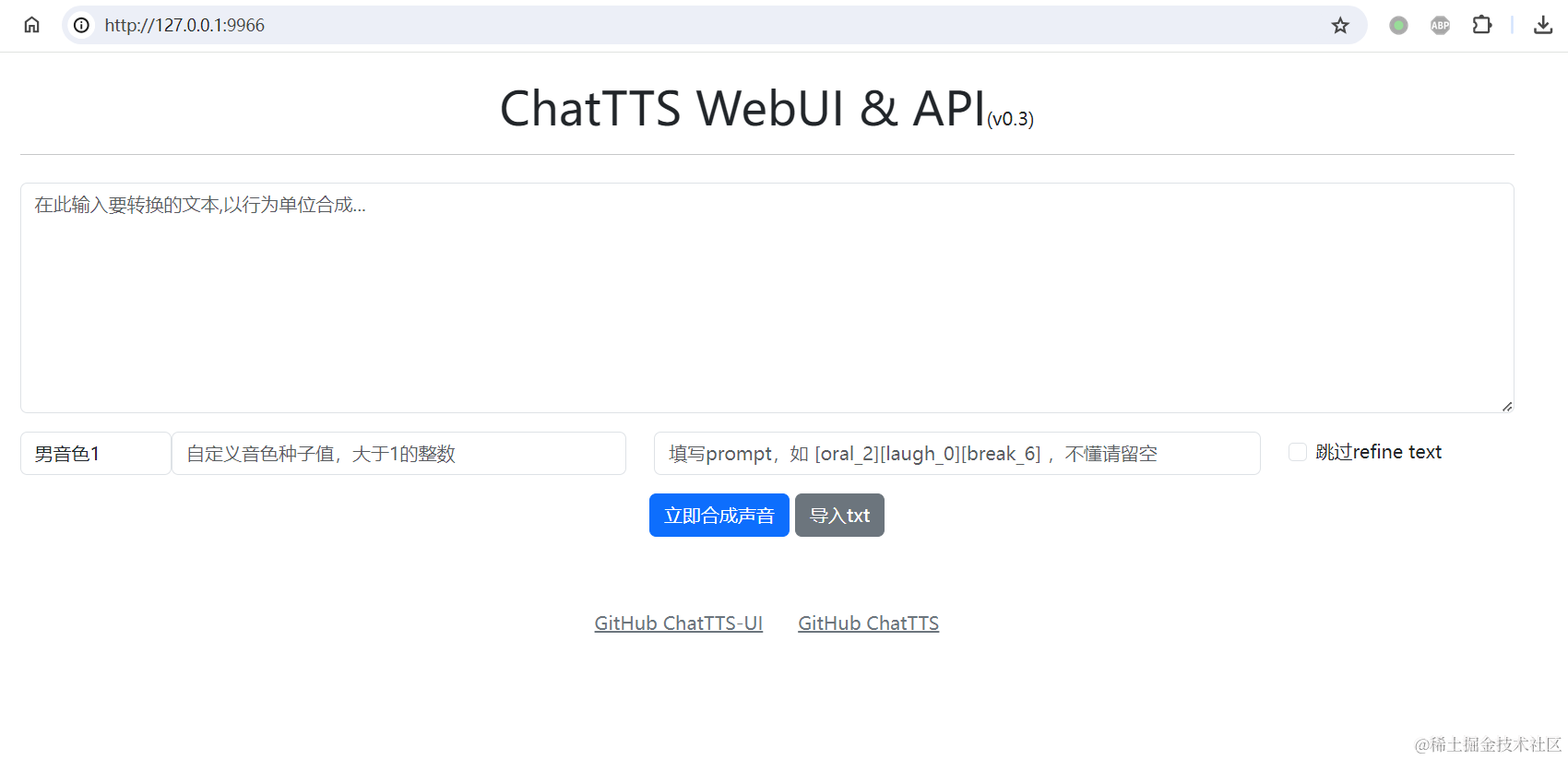
WebUI界面和整合包
开源和下载地址 https://github.com/jianchang512/chatTTS-ui
整合包解压后双击 app.exe
源码部署按仓库说明
UI界面预览